一、主从复制
1、概念
- 一个master可以拥有多个slave。
- master的复制是异步非阻塞的。
- 客户端可以使用wait命令请求同步复制某些特定数据。
- 正常连接情况下,master通过命令流来保持对slave的数据更新。
- master与slave之间得到连接断开,slave在尝试与master重连后,会尝试获取与master断开期间丢失的命令流
- 当断开期间的数据无法重新同步时,slave会请求全量更新,master将以rdb快照方式将全量数据推送给slave,之后再进行增量更新。
2、复制原理
- 每个master都有一个replicationId用来表示与slave处于同一个主从复制中;
同时存在一个偏移量,用来记录上次发送给slave的数据,每次复制数据后该偏移量都会增加,即使没有slave链接master,它的offset也会增加。一对Replication ID, offset表示一个版本的数据 - 当slave连接到master后,会使用psync命令发送自己存储的旧replicationId和offset,master从积压的缓冲区找到对应版本的数据,开始增量复制推送给slave,如果缓冲区没有的话,master会进行全量RBD复制
- 全量复制,master后台fork一个进行产生一个rdb文件在本地磁盘,将rdb文件传输给slave保存在本地磁盘,slave加载到内存执行,无磁盘复制可以使用repl-diskless-sync 配置参数
3、准备
1 | #创建文件夹,拷贝redis配置,方便后续测试 |
4、启动redis
1 | redis-server ./6379.conf |
5、slave追随master
1 | 方式一:在进入6380、6381客户端,使用`replicaof host port`命令(5.0之前命令为`slaveof host port`),让从节点追随主节点 |
从节点控制台日志

主节点控制台日志

6、错误
此时发现客户端宕机,重新启动客户端报如下错误
6.1、问题1:
1 | WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect. |
执行sysctl vm.overcommit_memory=1解决以上问题
6.2、问题2:
1 | WARNING you have Transparent Huge Pages (THP) support enabled in your kernel. This will create latency and memory usage issues with Redis. To fix this issue run the command 'echo madvise > /sys/kernel/mm/transparent_hugepage/enabled' as root, and add it to your /etc/rc.local in order to retain the setting after a reboot. Redis must be restarted after THP is disabled (set to 'madvise' or 'never'). |
执行echo madvise > /sys/kernel/mm/transparent_hugepage/enabled解决以上问题
6.3、问题3:
1 | The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128. |
执行echo 511 > /proc/sys/net/core/somaxconn解决以上问题
6.4、问题4:
1 | 5499:M 13 Apr 2021 21:58:45.198 # Server initialized |
此时仍无法启动,需要到持久化目录/var/lib/redis/6381下处理rdb文件mv dump.rdb dump.rdb.bak,此时可以正常启动
7、slave升级为master
当主节点宕机时,我们需要手动进行故障转移,将从节点升级为主节点

从节点客户端执行replicaof no one指令,将自己从slave升级为master

8、配置
1 | # slave在首次接收master数据时,可以在slave中配置同步期间是否接收旧数据的访问,在首次同步之后,旧数据会被删除,然后再主线程加载新数据,此时slave会阻塞 |
9、总结
1、从节点追随主节点之后,旧数据会被删除,同时非阻塞方式同步主节点数据
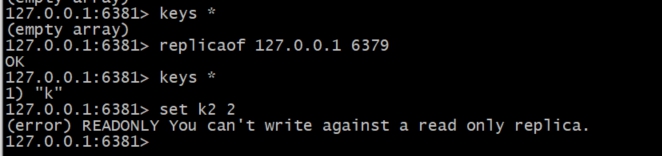
2、从节点只能读,不能写(可修改配置改变)
3、主节点出现故障时,需要人工维护升级新的主节点
二、哨兵模式
1、概念
1 | 1.通过连接master获取slave的信息 |
2、Sentinel相互发现
- 每个Sentinel会以每两秒一次的频率,通过发布与订阅功能,向被它监视的所有master和slave的 sentinel:hello 频道发送一条信息,信息中包含了该Sentinel的IP 地址、端口号和运行ID (runid)。
- 每个Sentinel都订阅了被它监视的所有master和slave的sentinel:hello 频道,查找之前未出现过的sentinel(looking for unknown sentinels)。当一个Sentinel 发现一个新的Sentinel时,它会将新的Sentinel添加到一个列表中,这个列表保存了Sentinel已知的,监视同一个主服务器的所有其他Sentinel。
- Sentinel 发送的信息中还包括完整的主服务器当前配置(configuration)。 如果一个 Sentinel 包含的主服务器配置比另一个 Sentinel 发送的配置要旧, 那么这个 Sentinel 会立即升级到新配置上。
- 在将一个新Sentinel添加到监视主服务器的列表上面之前,Sentinel会先检查列表中是否已经包含了和要添加的Sentinel拥有相同运行ID或者相同地址(包括IP地址和端口号)的 Sentinel ,如果是的话,Sentinel会先移除列表中已有的那些拥有相同运行ID或者相同地址的Sentinel, 然后再添加新Sentinel。
3、Sentinel对master的故障判定
1)、 Sentinel以每秒钟一次的频率向它所知的master、slave以及其他 Sentinel 实例发送一个 PING 命令,如果距离最后一次有效回复 PING 命令的时间超过 down-after-milliseconds 选项所指定的值,那么这个实例会被 Sentinel 标记为主观下线。一个有效回复可以是:+PONG 、-LOADING 或者 -MASTERDOWN ,其余回复或者没有回复都算是无效回复。
2)、当master标记为ODOWN(主观下线)后,用通过向另一个 Sentinel 发送 SENTINEL is-master-down-by-addr 命令来询问对方是否认为给定的服务器已下线。
2.1)、当有足够数量的 Sentinel(至少要达到配置文件指定的数量quorum)在指定的时间范围内同意这一判断, 那么这个主服务器被标记为客观下线。
2.2)、当没有足够数量的 Sentinel 同意主服务器已经下线, 主服务器的客观下线状态就会被移除。 当主服务器重新向 Sentinel 的 PING 命令返回有效回复时, 主服务器的主观下线状态就会被移除
3)、在一般情况下, 每个 Sentinel 会以每 10 秒一次的频率向它已知的所有master和slave发送 INFO 命令。 当一个master被 Sentinel 标记为客观下线时, Sentinel 向下线master的所有slave发送 INFO 命令的频率会从 10 秒一次改为每秒一次。
4、选举新的master
1 | 首先标记master为ODOWN状态的Sentinel使用以下规则从slave中来选取新的master: |
5、准备
1 | #配置文件参考源码目录下/usr/local/redis-6.0.9/sentinel.conf |
6、配置
1 | #如果需要监控监控的master设置了密码,需要在此处设置 |
7、启动哨兵节点
1 | 启动方式一:redis-server ./26379.conf --sentinel |
8、选举新master节点
当master节点宕机,哨兵节点过半以上检测到之后会重新选举新的master节点


slave节点升级为master节点

另一个slave检测到新的master主节点产生并追随

总结
1、哨兵通过主节点获取从节点信息,同时发布订阅方式发现其他哨兵节点信息
2、主节点宕机后,哨兵节点重新选举新的主节点,做到故障转移,不需要人工处理
3、master节点存在已经过期的key,复制到了slave,那当master的“访问过期”和“定期过期”机制没有被触发时,该key没有被删除,客户端链接slave查询该key时出现什么情况?推测:判断过期返回不存在,过期的key不处理,等待master处理后同步del指令
三、分区
1、概念
1.1、不同端的分区
1 | 客户端分区: |
1.2、优缺点
1 | 分区优点 |
1.3、预分片
因为redis实例占用的内存很小,在一台机子提前启用多台redis以分布式方式运行,随着数据不断增加,需要做的只是将redis实例迁移到另外的计算机中,不需要考虑重新分区
1 | 1.新的服务器启动新的redis实例 |
2、分区算法
2.1、普通Hash算法(modula)
1 | 比如你有 N 个 `redis`实例,那么如何将一个`key`映射到`redis`上呢,你很可能会采用类似下面的通用方法计算 key的 hash 值,然后均匀的映射到到 N 个 `redis`上: |
2.2、随机分配算法(random)
1 | 随机将数据分发到Redis集群中,Client无法准确地从某台机器获取相对的数据,该做法常用于消息队列中。 |
2.3、一致性Hash算法(ketama)
- 将内存想象成一个环,由于hash值有32位,因此将内存分出2 ^32(0~2 ^32-1)个地址
- 将节点的IP+算法确定唯一的哈希值,之后在内存中确定节点的位置
- 当保存数据时,根据key进行哈希运算,确定唯一的一个位置
- 根据当前
key位置顺时针查找最近的node节点进行挂载(在内存中,加法计算快于减法运算,因此采用顺时针查找)
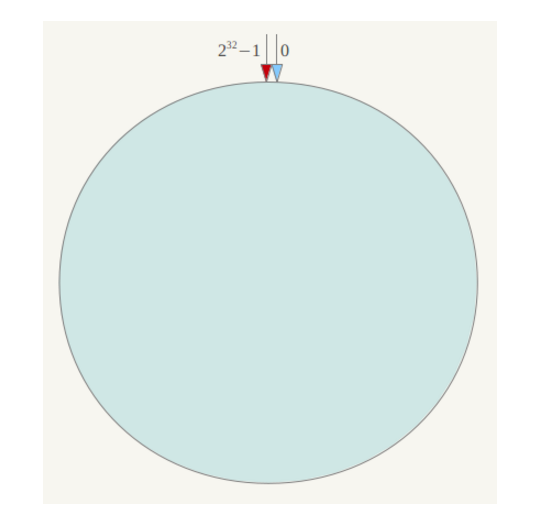
将各个服务器使用Hash进行一个哈希,具体可以选择服务器的ip或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置。
假设将中四台服务器使用ip地址哈希后在环空间的位置如下:
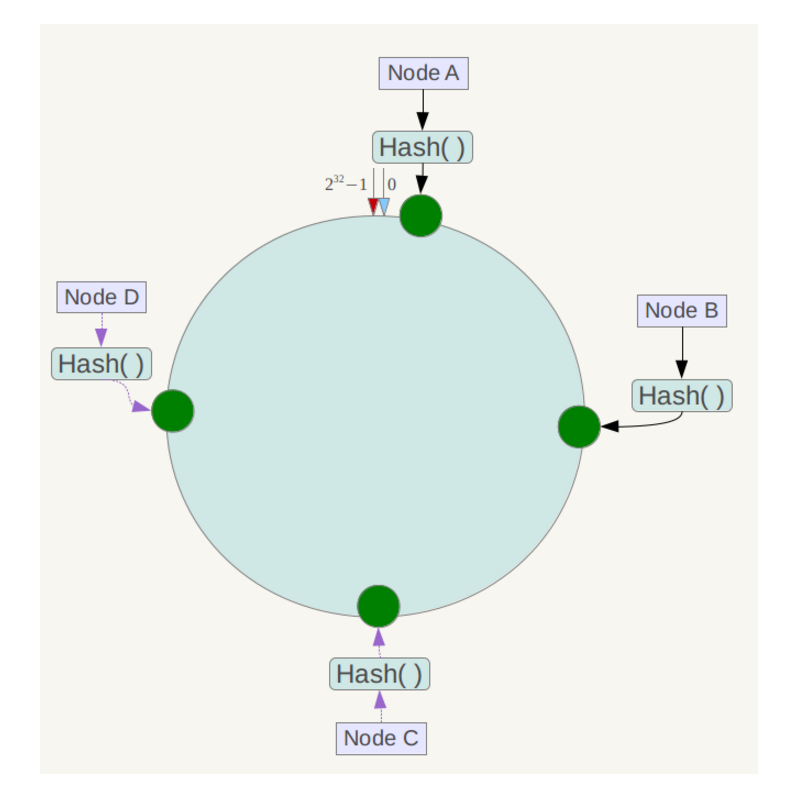
将数据key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器。
假设4个存储对象 Object A、B、C、D,经过对 Key 的哈希计算后,它们的位置如下:
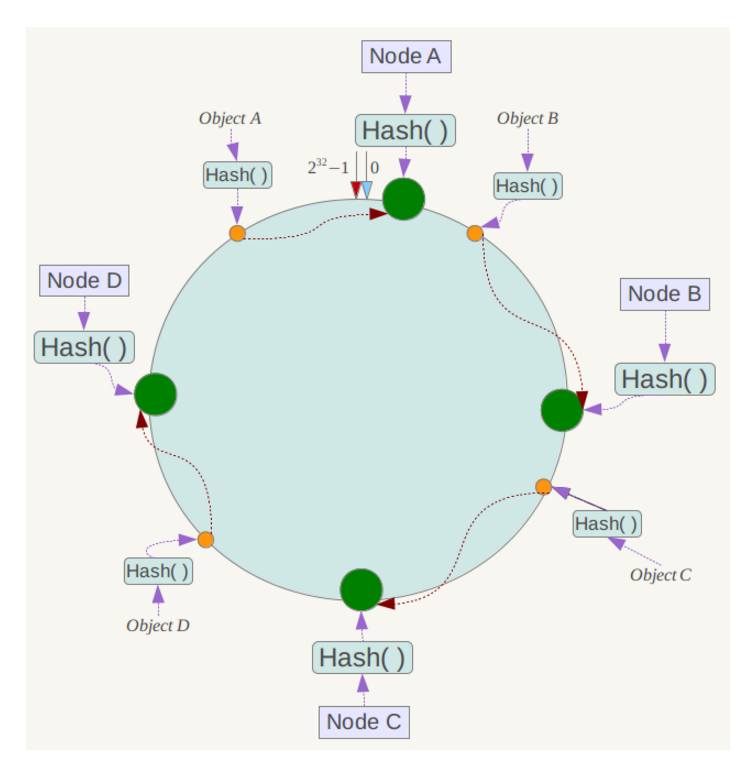
根据一致性哈希算法,数据A会被定为到Node A上,B被定为到Node B上,C被定为到Node C上,D被定为到Node D上。
容错性和可扩展性
假设Node C不幸宕机,可以看到此时对象A、B、D不会受到影响,只有C对象被重定位到Node D。一般的,在一致性哈希算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。
如果在系统中增加一台服务器Node X,如下图所示:

此时对象Object A、B、D不受影响,只有对象C需要重定位到新的Node X 。一般的,在一致性哈希算法中,如果增加一台服务器,则受影响的数据仅仅是新服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它数据也不会受到影响。
综上所述,一致性哈希算法对于节点的增减都只需重定位环空间中的一小部分数据,具有较好的容错性和可扩展性。
如果这时候新增了一个结点,对原来缓存的一部分数据的访问将会落到新增的结点上,但是这时候结点并没有数据缓存,它将去数据库中查找并缓存,原先已经缓存数据的结点需要通过淘汰算法(LRU)淘汰数据,它并没有从原缓存结点复制数据到新节点中。
虚拟节点
但一致性哈希算法也有一个严重的问题,就是数据倾斜。如果在分片的集群中,节点太少,并且分布不均,一致性哈希算法就会出现部分节点数据太多,部分节点数据太少。也就是说无法控制节点存储数据的分配。如下图,大部分数据都在 A 上了,B 的数据比较少。
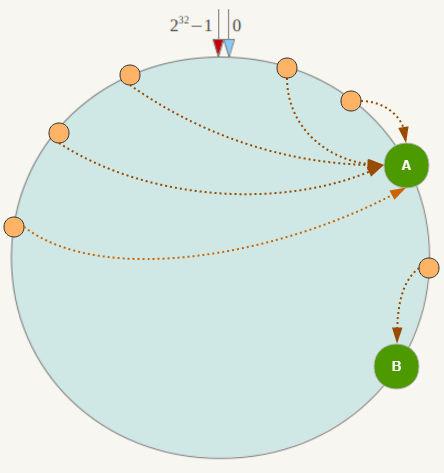
节点数越少,越容易出现节点在哈希环上的分布不均匀,导致各节点映射的对象数量严重不均衡(数据倾斜);相反,节点数越多越密集,数据在哈希环上的分布就越均匀。
以删除节点为例,假设删除了Node B节点,原来Node B节点的数据将转移到Node C上,这样Node C的内存使用率会骤增,如果Node B上存在热点数据,Node C会扛不住甚至会可能挂掉,挂掉之后数据又转移给Node D,如此循环会造成所有节点崩溃,也就是缓存雪崩。
为了解决雪崩现象和数据倾斜现象,提出了虚拟节点这个概念。就是将真实节点计算多个哈希形成多个虚拟节点并放置到哈希环上,定位算法不变,只是多了一步虚拟节点到真实节点映射的过程
但实际部署的物理节点有限,我们可以用有限的物理节点,虚拟出足够多的虚拟节点(Virtual Node),最终达到数据在哈希环上均匀分布的效果。
如下图,实际只部署了2个节点 Node A/B,每个节点都复制成3倍,结果看上去是部署了6个节点。可以想象,当复制倍数为 2^32 时,就达到绝对的均匀,通常可取复制倍数为32或更高。
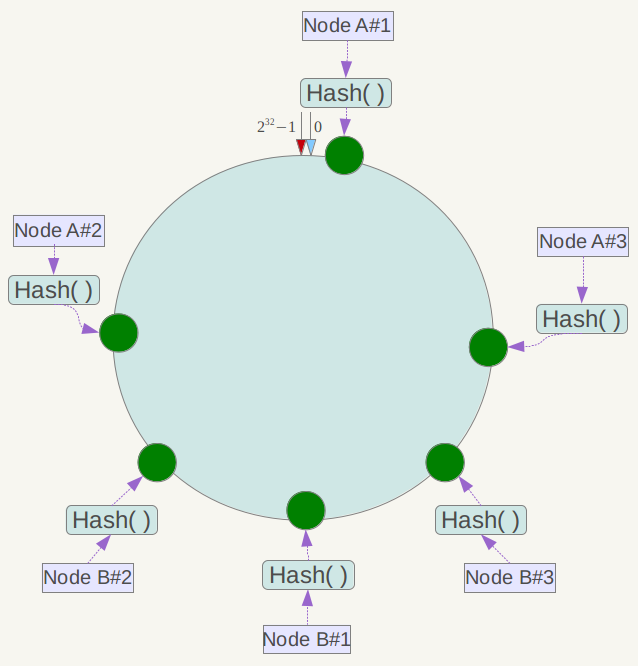
这就解决了雪崩的问题,当某个节点宕机后,其数据并没有全部分配给某一个节点,而是被分到了多个节点,数据倾斜的问题也随之解决。
实现
一致性哈希算法,既可以在客户端实现,也可以在中间件上实现(如 proxy)。在客户端实现中,当客户端初始化的时候,需要初始化一张预备的 Redis 节点的映射表:hash(key)=> . 这有一个缺点,假设有多个客户端,当映射表发生变化的时候,多个客户端需要同时拉取新的映射表。
另一个种是中间件(proxy)的实现方法,即在客户端和 Redis 节点之间加多一个代理,代理经过哈希计算后将对应某个 key 的请求分发到对应的节点,一致性哈希算法就在中间件里面实现。可以发现,twemproxy 就是这么做的。
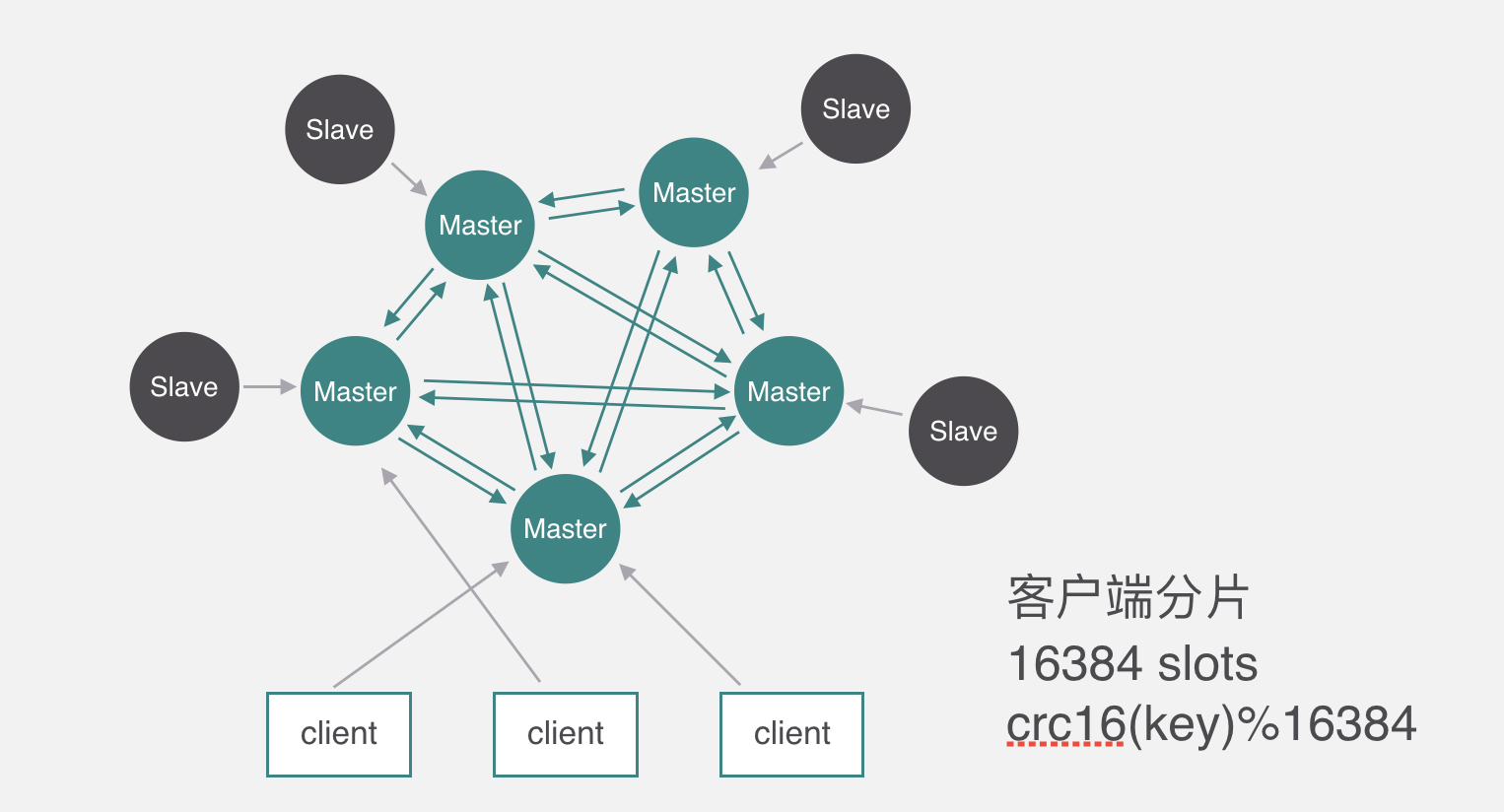
2.4、哈希槽
redis 集群(cluster)并没有选用上面一致性哈希,而是采用了哈希槽(slot)的这种概念。主要的原因就是上面所说的,一致性哈希算法对于数据分布、节点位置的控制并不是很友好。
首先哈希槽其实是两个概念,第一个是哈希算法。redis cluster 的 hash 算法不是简单的hash(),而是 crc16 算法,一种校验算法。另外一个就是槽位的概念,空间分配的规则。
其实哈希槽的本质和一致性哈希算法非常相似,不同点就是对于哈希空间的定义。一致性哈希的空间是一个圆环,节点分布是基于圆环的,无法很好的控制数据分布。而 redis cluster 的槽位空间是自定义分配的,类似于 windows 盘分区的概念。这种分区是可以自定义大小,自定义位置的。
redis cluster 包含了16384个哈希槽,每个 key 通过计算后都会落在具体一个槽位上,而这个槽位是属于哪个存储节点的,则由用户自己定义分配。例如机器硬盘小的,可以分配少一点槽位,硬盘大的可以分配多一点。如果节点硬盘都差不多则可以平均分配。所以哈希槽这种概念很好地解决了一致性哈希的弊端。
当有新节点加入时,它不再需要像一致性Hash算法那样把每个key取出来重新计算hash值,只需要从旧节点中将新节点应该缓存的槽位数据拷贝到新节点中即可。
另外在容错性和扩展性上,表象与一致性哈希一样,都是对受影响的数据进行转移。而哈希槽本质上是对槽位的转移,把故障节点负责的槽位转移到其他正常的节点上。扩展节点也是一样,把其他节点上的槽位转移到新的节点上。
弊端是聚合操作很难实现,并且不支持跨机器事务,但是提供了Hash Tag让用户控制需要计算的Key都集中在一个Redis中。
3、代理分区-TwemProxy
3.1、安装
1 | git clone git@github.com:twitter/twemproxy.git |
3.2、配置
1 | vim nutcracker.yml |
3.3、手动启动redis
1 | #直接指定端口启动的话,会将当前目录作为持久目录 |
3.4、启动twemproxy
1 | service twemproxy start |

3.5、通过代理连接redis
1 | #数据分区,不支持keys、watch、MULTI等命令 |
4、代理分区-Predixy
4.1、安装
1 | wget https://github.com/joyieldInc/predixy/releases/download/1.0.5/predixy-1.0.5-bin-amd64-linux.tar.gz |
4.2、predixy相关配置
1 | #修改predixy配置 |
4.3、sentinel配置
1 | port 26379 |
4.4、启动sentinel
1 | redis-server 26379.conf --sentinel |
4.5、启动redis主从
1 | mkdir 36379 |
4.6、启动predixy
1 | cd /usr/local/predixy/predixy-1.0.5/bin |

4.7、通过代理连接redis
1 | #代理分区,因为sentinel监控了两套主从,不支持keys、watch、MULTI等命令,使用单套主从则可以 |

5、查询路由分区-Redis-Cluster
1 | 无需`proxy`代理,客户端直接与`redis`集群的每个节点连接,根据同样的`hash`算法计算出`key`对应的`slot`,然后直接在`slot`对应的`redis`节点上执行命令。 |
5.1、slot分配
redis集群模式使用公式 CRC16(key) % 16384 来计算键key属于哪个槽, 其中 CRC16(key) 语句用于计算键 key 的 CRC16 校验和 。集群中的每个节点负责处理一部分哈希槽。
举个例子, 一个集群可以有三个节点, 其中:
- 节点 A 负责处理 0 号至 5500 号哈希槽。
- 节点 B 负责处理 5501 号至 11000 号哈希槽。
- 节点 C 负责处理 11001 号至 16383 号哈希槽。
- 此时
Redis Client需要根据一个Key获取对应的Value的数据,首先通过CRC16(key)%16384计算出 Slot 的值,假设计算的结果是 5000,将这个数据传送给Redis Cluster,集群接收到以后会到一个对照表中查找这个Slot=5000属于那个缓存节点。发现属于“节点 A ”负责,于是顺着红线的方向调用节点 A中存放的Key-Value的内容并且返回给Redis Client。
这种将哈希槽分布到不同节点的做法使得用户可以很容易地向集群中添加或者删除节点。 比如说:
- 如果用户将新节点 D 添加到集群中, 那么集群只需要将节点 A 、B 、 C 中的某些槽移动到节点 D 就可以了。
- 如果用户要从集群中移除节点 A , 那么集群只需要将节点 A 中的所有哈希槽移动到节点 B 和节点 C , 然后再移除空白(不包含任何哈希槽)的节点 A 就可以了。
因为将一个哈希槽从一个节点移动到另一个节点不会造成节点阻塞,且成本很低, 所以无论是添加新节点还是移除已存在节点, 又或者改变某个节点包含的哈希槽数量, 都不会造成集群下线。
5.2、数据结构
Redis Cluster中的每个节点都保存了集群的配置信息,并且存储在clusterState中,结构如下:

上图的各个变量语义如下:
clusterState记录了从集群中某个节点视角,来看集群配置状态;currentEpoch表示整个集群中最大的版本号,集群信息每变更一次,改版本号都会自增。nodes是一个列表,包含了本节点所感知的,集群所有节点的信息(clusterNode),也包含自身的信息。clusterNode记录了每个节点的信息,其中包含了节点本身的版本Epoch;自身的信息描述:节点对应的数据分片范围(slot)、为master时的slave列表、为slave时的master等。
每个节点包含一个全局唯一的NodeId。
当集群的数据分片信息发生变更(数据在节点间迁移时),Redis Cluster仍然保持对外服务。
当集群中某个master出现宕机时,Redis Cluster 会自动发现,并触发故障转移的操作。会将master的某个slave晋升为新的 master。
由此可见,每个节点都保存着Node视角的集群结构。它描述了数据的分片方式,节点主备关系,并通过Epoch作为版本号实现集群结构信息的一致性,同时也控制着数据迁移和故障转移的过程。
5.3、节点通信
在Redis Cluster中,这个配置信息交互通过Redis Cluster Bus来完成(独立端口)。Redis Cluster Bus上交互的信息结构如下:

clusterMsg 中的type指明了消息的类型,配置信息的一致性主要依靠PING/PONG。每个节点向其他节点频繁的周期性的发送PING/PONG消息。对于消息体中的Gossip部分,包含了sender/receiver 所感知的其他节点信息,接受者根据这些Gossip 跟新对集群的认识。
对于大规模的集群,如果每次PING/PONG 都携带着所有节点的信息,则网络开销会很大。此时Redis Cluster 在每次PING/PONG,只包含了随机的一部分节点信息。由于交互比较频繁,短时间的几次交互之后,集群的状态也会达成一致。
5.4、一致性
当Cluster 结构不发生变化时,各个节点通过gossip 协议在几轮交互之后,便可以得知Cluster的结构信息,达到一致性的状态。但是当集群结构发生变化时(故障转移/分片迁移等),优先得知变更的节点通过Epoch变量,将自己的最新信息扩散到Cluster,并最终达到一致。
clusterNode 的Epoch描述的单个节点的信息版本;clusterState 的currentEpoch 描述的是集群信息的版本,它可以辅助Epoch 的自增生成。因为currentEpoch 是维护在每个节点上的,在集群结构发生变更时,Cluster 在一定的时间窗口控制更新规则,来保证每个节点的currentEpoch都是最新的。
更新规则如下:
当某个节点率先知道了变更时,将自身的currentEpoch 自增,并使之成为集群中的最大值。再用自增后的currentEpoch 作为新的Epoch 版本;
- 当某个节点收到了比自己大的
currentEpoch时,更新自己的currentEpoch; - 当收到的
Redis Cluster Bus消息中的某个节点的Epoch> 自身的时,将更新自身的内容; - 当
Redis Cluster Bus消息中,包含了自己没有的节点时,将其加入到自身的配置中。
上述的规则保证了信息的更新都是单向的,最终朝着Epoch更大的信息收敛。同时Epoch也随着currentEpoch的增加而增加,最终将各节点信息趋于稳定。
为了使得集群在一部分节点下线或者无法与集群的大多数(majority)节点进行通讯的情况下, 仍然可以正常运作, Redis 集群对节点使用了主从复制功能: 集群中的每个节点都有 1 个至 N 个复制品(replica), 其中一个复制品为主节点(master), 而其余的 N-1 个复制品为从节点(slave)。
集群间节点支持主从关系,复制的逻辑基本复用了单机版的实现。不过还是有些地方需要注意。
- 首先集群间节点建立主从关系不再使用原有的
SLAVEOF命令和SLAVEOF配置,而是通过cluster replicate命令,这保证了主从节点需要先完成握手,才能建立主从关系。 - 集群是不能组成链式主从关系的,也就是说从节点不能有自己的从节点。不过对于集群外的没开启集群功能的节点,
redis并不干预这些节点去复制集群内的节点,但是在集群故障转移时,这些集群外的节点,集群不会处理。 - 集群内节点想要复制另一个节点,需要保证本节点不再负责任何
slot,不然redis也是不允许的。 - 集群内的从节点在与其他节点通信的时候,传递的消息中数据分布表和
epoch是master的值。
集群主节点出现故障,发生故障转移,其他主节点会把故障主节点的从节点自动提为主节点,原来的主节点恢复后,自动成为新主节点的从节点。
这里先说明,把一个master和它的全部slave描述为一个group,故障转移是以group为单位的,集群故障转移的方式跟sentinel的实现很类似。

5.5、均衡集群
在集群运行过程中,有的master的slave宕机,导致了该master成为孤儿master(orphaned masters),而有的master有很多slave。
此处孤儿master的定义是那些本来有slave,但是全部离线的master,对于那些原来就没有slave的master不能认为是孤儿master。
redis集群支持均衡slave功能,官方称为Replica migration,而我觉得均衡集群的slave更好理解该概念。集群能把某个slave较多的group上的slave迁移到那些孤儿master上,该功能通过cluster-migration-barrier参数配置,默认为1。
slave在每次定时任务都会检查是否需要迁移slave,即把自己变成孤儿master的slave。 满足以下条件,slave就会成为孤儿master的slave:
- 自己所在的
group是slave最多的group。 - 目前存在孤儿
master。 - 自己所在的
group的slave数目至少超过2个,只有自己一个的话迁移到其他group,自己原来的group的master又成了孤儿master。 - 自己所在的
group的slave数量大于cluster-migration-barrier配置。 - 与
group内的其他slave基于memcmp比较node id,自己的node id最小。这个可以防止多个slave并发复制孤儿master,从而原来的group失去过多的slave。
5.5.1、优势
- 去中心化,集群最大可增加1000个节点,性能随节点增加而线性扩展。
- 解耦 数据 和 节点 之间的关系,简化了节点 扩容 和 收缩 难度。
- 节点自身 维护槽的 映射关系,不需要 客户端 或者 代理服务 维护 槽分区元数据。
5.5.2、劣势
key批量操作 支持有限。类似mset、mget操作,目前只支持对具有相同slot值的key执行 批量操作。对于 映射为不同slot值的key由于执行mget、mget等操作可能存在于多个节点上,因此不被支持。- 只支持 多
key在 同一节点上 的 事务操作,当多个key分布在 不同 的节点上时 无法 使用事务功能。 key作为 数据分区 的最小粒度,不能将一个 大的键值 对象如hash、list等映射到 不同的节点。- 不支持多数据库空间,单机下的
Redis可以支持 16 个数据库(db0 ~ db15),集群模式下只能使用一个 数据库空间,即 db0。 - 复制结构 只支持一层,从节点 只能复制 主节点,不支持 嵌套树状复制 结构。
5.6、集群搭建
5.6.1、脚本启动
进入redis源码目录下/utils/create-cluster中执行create-cluster脚本
cd /usr/local/redis-6.0.9/utils/create-cluster
5.6.2、配置
vim create-cluster
1 | # Settings |
由以上配置可以看出,总节点数为6,每个master对应的slave数量为1,因此根据此配置启动后集群为三主三从模式;后续如果有需要可以修改此配置
5.6.3、启动集群实例
./create-cluster start

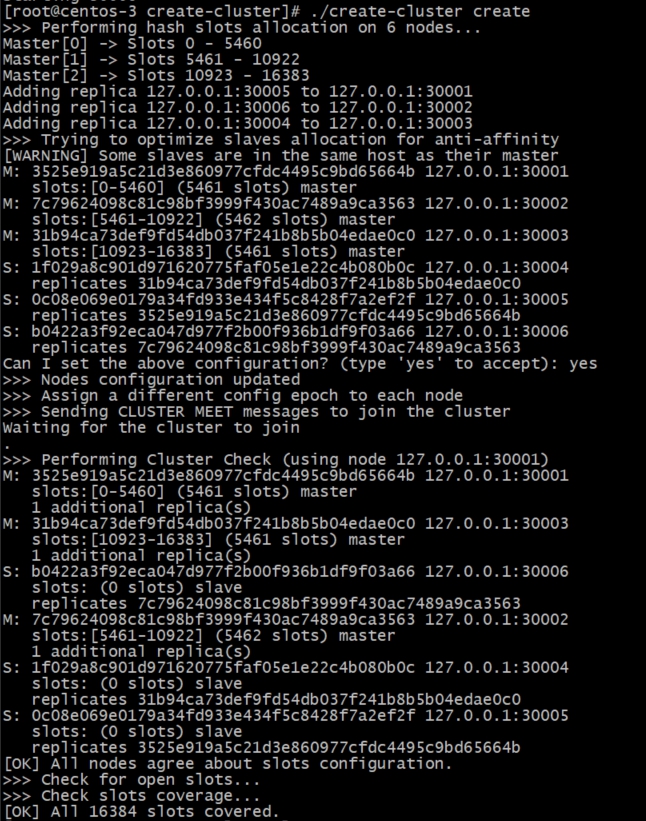
5.6.4、脚本分配slot(hash槽位)
./create-cluster create
5.6.5、客户端-连接
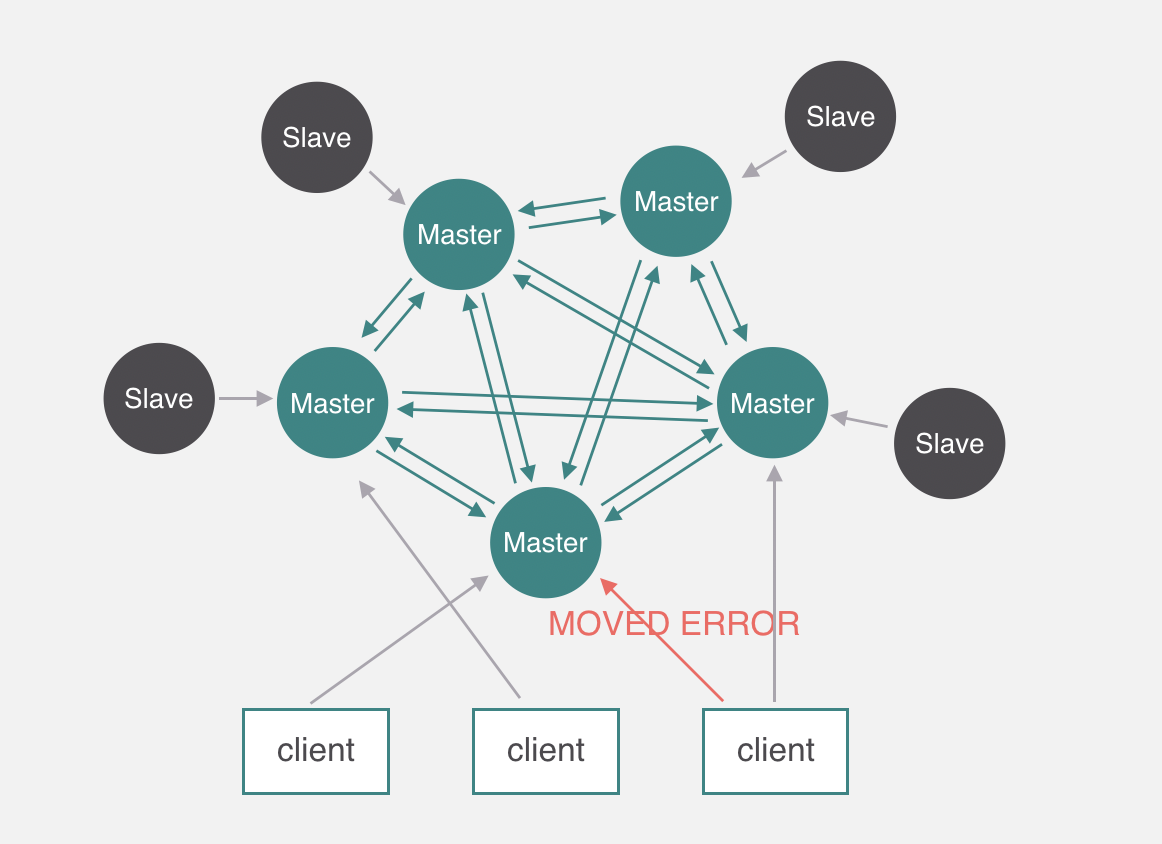
客户端在初始化的时候只需要知道一个节点的地址即可,客户端会先尝试向这个节点执行命令,比如“get key”,如果key所在的slot刚好在该节点上,则能够直接执行成功。如果slot不在该节点,则节点会返回MOVED错误,同时把该slot对应的节点告诉客户端。客户端可以去该节点执行命令。
普通客户端模式-连接
redis-cli -p 30001
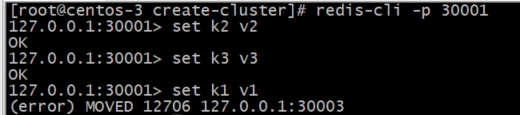
key分配的slot不在当前连接的redis server时,服务端返回错误提示,让客户端自己进行跳转 (error) MOVED 12706 127.0.0.1:30003
集群客户端模式-连接
redis-cli -c -p 30001
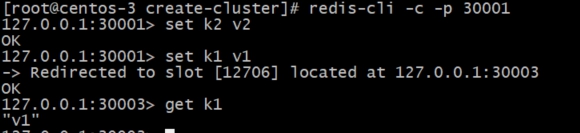
key分配的slot不在当前连接的redis server时,集群模式客户端会帮助我们进行重定向跳转 Redirected to slot [12706] located at 127.0.0.1:30003
5.6.6、注意
1 | 不管是`普通客户端模式`还是`集群客户端模式`去连接服务,如果key不在一个slot仍无法使用事务等指令 |
5.6.7、停止实例
停止所有正在运行的redis-cluster实例 ./create-cluster stop
5.6.7、还原实例
清除配置、日志、持久化文件 ./create-cluster clean

5.6.8、手动启动
修改redis配置,之后启动redis时加载此配置 redis-server ./6379.conf
1 | ################################ REDIS CLUSTER ############################### |
5.6.9、手动分配slot(hash槽)
使用此方式可以自己指定参与集群的redis节点,设置slave节点数,适合真实环境下多服务器实例的集群搭建
1 | redis-cli --cluster create 127.0.0.1:30001 127.0.0.1:30002 127.0.0.1:30003 127.0.0.1:30004 127.0.0.1:30005 127.0.0.1:30006 --cluster-replicas 1 |
5.6.10、移动slot
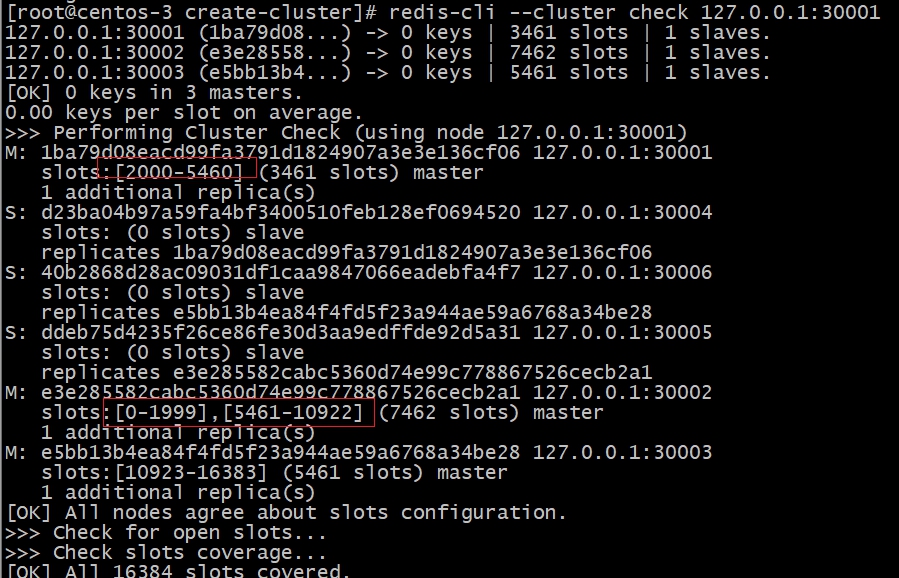
1 | #实行重新分片命令,可任意连接一个redis实例进行操作 |
如下图所示,有2000个槽位从30001的实例迁移到了30002的实例中
5.6.11、集群客户端-帮助
1 | [root@centos-3 create-cluster]# redis-cli --cluster help |