一、读写分离
通过mycat和mysql的主从复制配合搭建数据库的读写分离,可以实现mysql的高可用性。
修改mycat的schema.xml配置
1 |
|
writeType
表示写操作发送到哪台机器
- writeType=0:所有写操作都发送到配置的第一个writeHost,第一个挂了切换到还生存的第二个
- writeType=1:所有写操作都随机的发送到配置的writehost中,1.5之后废弃
switchType
表示如何进行切换
switchType=1:默认值,自动切换
switchType=-1:表示不自动切换
switchType=2:基于mysql主从同步的状态决定是否切换
验证
重启mycat restart
连接mycat mysql -uroot -pRoot_123 -P 8066 -h 192.168.243.131
执行插入语句 insert into t1 values(2,@@hostname);
分别连接四台mysql查询结果

连接mycat查询结果

到此,mysql双主双从结合mycat搭建读写分离完成,架构如下图所示

- 当查询时,会被分发到
slave-1、master-2、slave-2这三台机器上; - 当写操作时,会被分发到
master-1上; - 如果
master-1宕机,mycat会将写操作自动切换到master-2,之后如果master-1恢复(从master-2同步数据,slave-1再从master-1同步数据),也只提供读服务,写仍由master-2提供。
二、分库分表
数据的切分,主要有两种方式,分别是垂直切分和水平切分,所谓的垂直切分就是将不同的表分布在不同的数据库实例中,而水平切分指的是将一张表的数据按照不同的切分规则切分在不同实例的相同名称的表中。
1、分库
将不同的表分布在不同的库中,但是访问的时候使用的是同一个mycat的终端,这些操作都由mycat来完成的,我们只需修改相应的配置即可。
1.1、修改/etc/my.cnf文件
在mycat操作时它是不区分表明大小写的,需要在mysql的配置文件中添加lower_case_table_names=1参数,来保证查询的时候能够进行正常的查询。
1 | lower_case_table_names=1 |
1.2、重启mysql
1 | # 重启 |
1.3、修改schema.xml文件
1 |
|
1.4、重启mycat
1 | # 重启 |
1.5、停止master的slave服务
使用mycat进行分库操作之前,需要分别登陆master-1和master-2执行stop slave,将它们的主备关系去除,否则相互之间会进行数据同步,起不到分库的作用。
1 | -- 停止slave服务 |
登陆master-1和master-2的mysql服务分别创建my_db数据库
1 | create database my_db; |
1.6、验证
登陆mcat
1 | mysql -uroot -pRoot_123 -h 192.168.243.131 -P 8066 |
建表
1 | CREATE TABLE customer( |
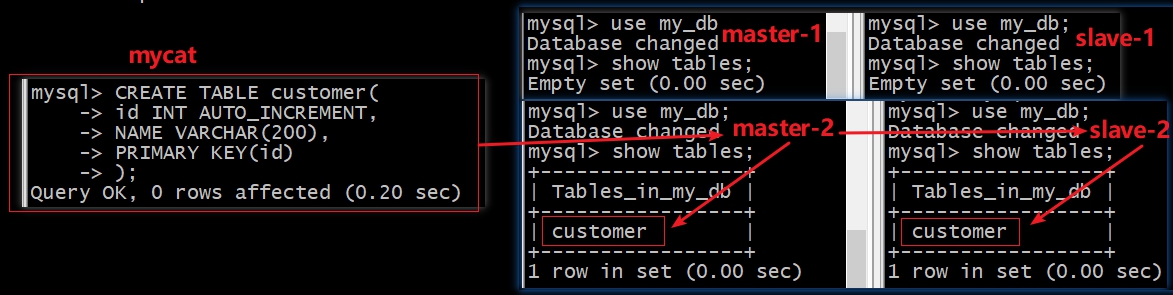
由上图可以看到,
mycat的建表语句被分发到了master-2执行,并且因为master-2与slave-2主从同步,slave-2也出现了customer表。
插入数据
1 | insert into customer values(1,'zhangsan'); |

由上图可以看到,
mycat插入的语句被分发到了master-2执行,并且因为master-2与slave-2主从同步,slave-2也出现了相关的数据。
2、分表(分片)
相对于垂直拆分,水平拆分不是将表做分类,而是按照某个字段的某种规则来分散到多个库之中,每个表中 包含一部分数据。简单来说,我们可以将数据的水平切分理解为是按照数据行的切分,就是将表中的某些行切分 到一个数据库,而另外的某些行又切分到其他的数据库中 。
2.1、取模运算
把customer_id按照取模运算进行数据拆分
修改schema.xml文件
在上文分库的schema文件基础上修改
1 | <schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"> |
修改rule.xml文件
配置取模运算规则
1 | <tableRule name="mod_rule"> |
重启mycat
建表
1 | CREATE TABLE orders( |
插入数据
1 | INSERT INTO orders(id,order_type,customer_id,amount) VALUES (1,101,100,100100); |
查询结果

由上图可以看出,
mycat会将我们插入的数据根据customer_id字段值%2,结果为0的分发到master-1,为1分发master-2
2.2、分片枚举
通过在配置文件中配置可能存在的值,配置分片。
修改schema.xml文件
1 | <schema name="TESTDB" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"> |
修改rule.xml文件
1 | <tableRule name="sharding_by_intfile"> |
修改partition-hash-int.txt文件
1 | #10000=0 |
重启mycat
建表
1 | CREATE TABLE orders_ware_info |
插入数据
1 | INSERT INTO orders_ware_info(id, order_id,address,areacode) VALUES (1,1,'北京','110'); |

由上图可以看出,
mycat会将我们插入的数据根据areacode值与partition-hash-int.txt文件中配置参数比对确定存放的节点,110被分发到node-1,120被分发到node-2
2.3、范围分片
根据分片字段,约定好属于哪一个范围
修改schema.xml文件
1 | <table name="payment_info" dataNode="dn1,dn2" rule="auto-sharding-long" ></table> |
修改rule.xml文件
1 | <tableRule name="auto-sharding-long"> |
修改autopartition-long.txt文件
1 | # range start-end ,data node index |
重启mycat
建表
1 | CREATE TABLE payment_info |
插入数据
1 | INSERT INTO payment_info (id,order_id,payment_status) VALUES (1,101,0); |
查询结果
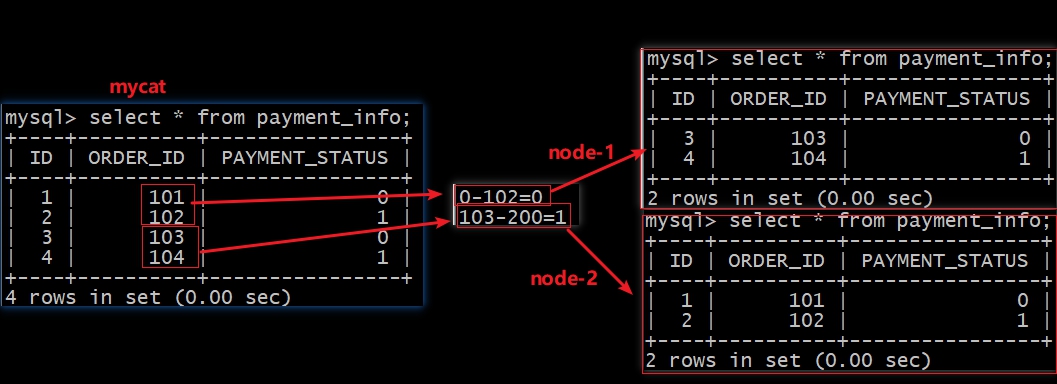
由上图可以看出,
mycat会将我们插入的数据根据order_id值与autopartition-long.txt文件中配置参数比对确定存放的节点
2.4、范围求模算法
该算法为先进行范围分片,计算出分片组,组内再求模,综合了范围分片和求模分片的优点。
分片组内使用求模可以保证组内的数据分步比较均匀,分片组之间采用范围分片可以兼顾范围分片的特点。事先规定好分片的数量,数据扩容时按分片组扩容,则原有分片组的数据不需要迁移。由于分片组内的数据分步比较均匀,所以分片组内可以避免热点数据问题。
修改schema.xml文件
1 | <table name="person" primaryKey="id" dataNode="dn1,dn2,dn3" rule="auto-sharding-rang-mod"></table> |
修改rule.xml文件
1 | <tableRule name="auto-sharding-rang-mod"> |
修改partition-range-mod.txt文件
1 | # range start-end ,data node group size |
重启mycat
建表
1 | CREATE TABLE `person` ( |
插入数据
1 | insert into person(id,name) values(9999,'zhangsan1'); |
查询结果
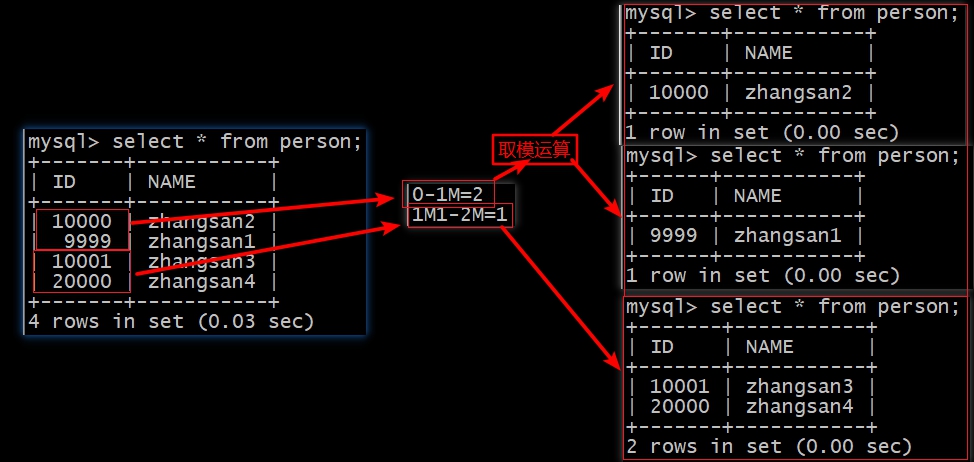
由上图可以看出,
mycat会将我们插入的数据根据id值与partition-range-mod.txt文件中配置参数比对,确定存放在哪个分片,如果该分片只有一个节点直接放入,分片存在多个节点时,需要对id值进行取模运算确定存放的节点先匹配范围,再取模
2.5、固定分片hash算法
类似于十进制的求模运算,但是为二进制的操作,取id的二进制低10位,即id的二进制 & 1111111111,结果落在0-1023之间,所以默认最大分片为1024.
此算法的优点在于如果按照十进制取模运算,则在连续插入110时,110会被分到1~10个分片,增大了插入事务的控制难度。而此算法根据二进制则可能会分到连续的分片,降低了插入事务的控制难度。
修改schema.xml文件
1 | <table name="user" primaryKey="id" dataNode="dn1,dn2,dn3" rule="rule1"></table> |
修改rule.xml文件
1 | <tableRule name="rule1"> |
重启mycat
建表
1 | CREATE TABLE `user` ( |
插入数据
1 | insert into user(id,name) values(1023,'zhangsan1'); |
查询结果
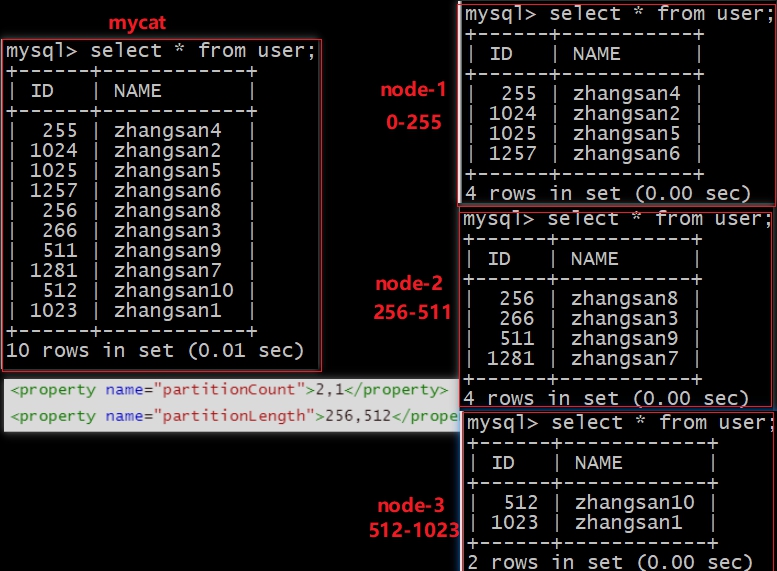
由上图可以看出,
mycat会将我们插入的数据根据id值与rule.xml文件中配置参数比对,确定存放在哪个分片,当数值超过1024时会减去1024再进行范围匹配最大分片数为1024,范围从0-1023
2.6、取模范围算法
取模运算与范围约束的结合主要是为后续的数据迁移做准备,即可以自主决定取模后数据的节点分布。
修改schema.xml文件
1 | <table name="user2" primaryKey="id" dataNode="dn1,dn2,dn3" rule="sharding-by-pattern"></table> |
修改rule.xml文件
1 | <tableRule name="sharding-by-pattern"> |
修改partition-pattern.txt文件
1 | 0-86=0 |
重启mycat
建表
1 | CREATE TABLE `user2` ( |
插入数据
1 | insert into user2(id,name) values(85,'zhangsan1'); |
查询结果

由上图可以看出,
mycat会将我们插入的数据根据id值与rule.xml文件中配置的取模基数patternValue进行计算,看结果落在哪个范围分片,最终确定存放在哪个节点先取模,再匹配范围
2.7、字符串hash求模范围算法
与取模范围算法类似,该算法支持数值、符号、字母取模,此方式就是将指定位数的字符的ascll码的和进行取模运算。
修改schema.xml文件
1 | <table name="user3" primaryKey="id" dataNode="dn1,dn2,dn3" rule="sharding-by-prefixpattern"></table> |
修改rule.xml文件
1 | <tableRule name="sharding-by-prefixpattern"> |
修改partition-pattern.txt文件
1 | # ASCII |
重启mycat
建表
1 | CREATE TABLE `user3` ( |
插入数据
1 | insert into user3(id,name) values(1,'zhangsan'); |
查询结果
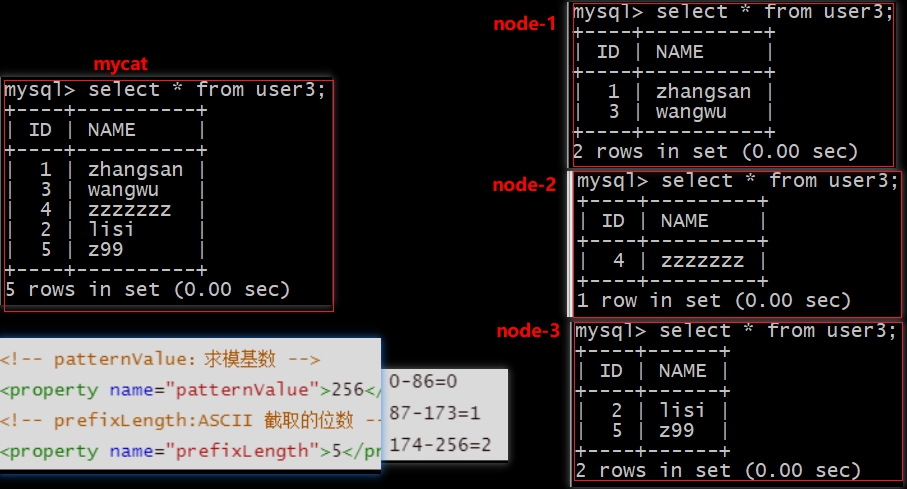
由上图可以看出,
mycat会将我们插入的数据根据name值的前五位进行截取计算ASCII值,结果值再与rule.xml文件中配置的取模基数patternValue进行取模计算,看取模结果落在哪个范围分片,最终确定存放在哪个节点先截取换算ASCII值,取模计算,再匹配范围
2.8、应用指定的算法
在运行阶段由应用程序自主决定路由到哪个分片。
修改schema.xml文件
1 | <table name="user4" primaryKey="id" dataNode="dn1,dn2,dn3" rule="sharding-by-substring"></table> |
修改rule.xml文件
1 | <tableRule name="sharding-by-substring"> |
重启mycat
建表
1 | CREATE TABLE `user4` ( |
插入数据
1 | insert into user4(id,name) values(1,'0-zhangsan'); |
查询结果

由上图可以看出,
mycat会将我们插入的数据根据name值从startIndex截取size数量的字符,结果值匹配分片的索引,最终确定存放在哪个节点
2.9、字符串hash解析算法
字符串hash解析分片,其实就是根据配置的hash预算位规则,将截取的字符串进行hash计算后,得到的int数值即为datanode index(分片节点索引,从0开始)。
修改schema.xml文件
1 | <table name="user5" primaryKey="id" dataNode="dn1,dn2,dn3" rule="sharding-by-stringhash"></table> |
修改rule.xml5文件
1 | <tableRule name="sharding-by-stringhash"> |
重启mycat
建表
1 | CREATE TABLE `user5` ( |
插入数据
1 | insert into user5(id,name) values(1111111,database()); |
查询结果

由上图可以看出,
mycat会将我们插入的数据中的id值根据hashslice截取合适的字符串进行hash值计算,再从长度是1024的数组中获取对应的节点索引值,将结果存入该节点最大分片数为1024,范围从0-1023
2.10、按照日期范围分片
按照某个指定的日期进行分片
修改schema.xml文件
1 | <table name="login_info" dataNode="dn1,dn2" rule="sharding_by_date" ></table> |
修改rule.xml文件
1 | <tableRule name="sharding_by_date"> |
重启mycat
建表
1 | CREATE TABLE login_info |
插入数据
1 | INSERT INTO login_info(id,user_id,login_date) VALUES (1,101,'2020-06-01'); |
查询结果
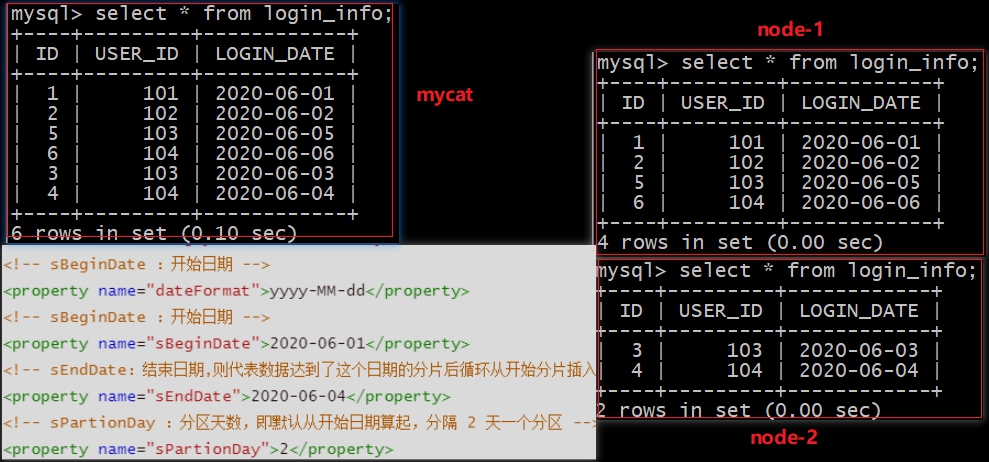
按照某个指定的日期进行分片,达到结束日期后循环开始分片插入
2.11、按单月小时分片
此规则是单月内按照小时拆分,最小粒度是小时,可以一天最多24个分片,最少一个分片,一个月完成后下个月开始循环,每个月月尾,需要手工清理数据。
修改schema.xml文件
1 | <table name="user6" dataNode="dn1,dn2,dn3" rule="sharding-by-hour"></table> |
修改rule.xml文件
1 | <tableRule name="sharding-by-hour"> |
重启mycat
建表
1 | create table user6( |
插入数据
1 | insert into user6(id,name,create_time) values(1,'steven','2020060100'); |
查询结果
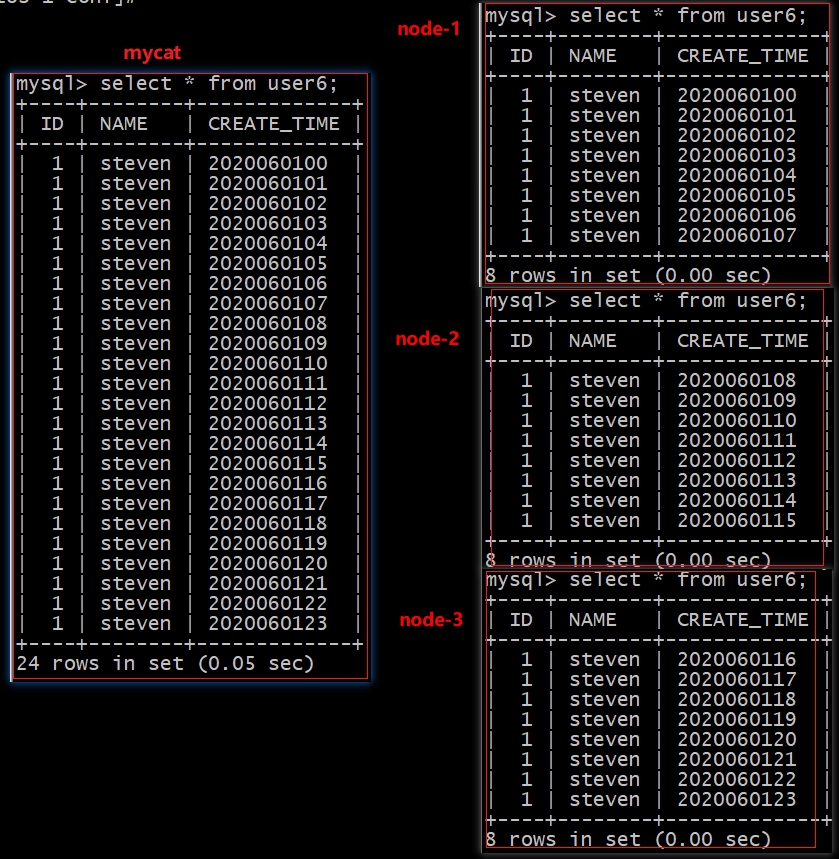
当运行完成之后会发现,第一天的数据能够正常的插入成功,均匀的分散到3个分片上,但是第二天的数据就无法成功分散了,原因就在于我们的数据分片不够,所以这种方式几乎没有人使用。
ERROR 1064 (HY000): Can’t find a valid data node for specified node index :USER6 -> CREATE_TIME -> 2020060200 -> Index : 3
2.12、日期范围hash分片
思想与范围求模一致,当由于日期在取模会有数据集中问题,所以改成了hash方法。先根据时间hash使得短期内数据分布的更均匀,有点可以避免扩容时的数据迁移,又可以一定程度上避免范围分片的热点问题,要求日期格式尽量精确,不然达不到局部均匀的目的。
修改schema.xml文件
1 | <table name="user7" dataNode="dn1,dn2,dn3" rule="rangeDateHash"></table> |
修改rule.xml文件
1 | <tableRule name="rangeDateHash"> |
重启mycat
建表
1 | create table user7( |
插入数据
1 | insert into user7(id,name,create_time) values(1,'steven','2020-06-01 00:00:00'); |
查询结果
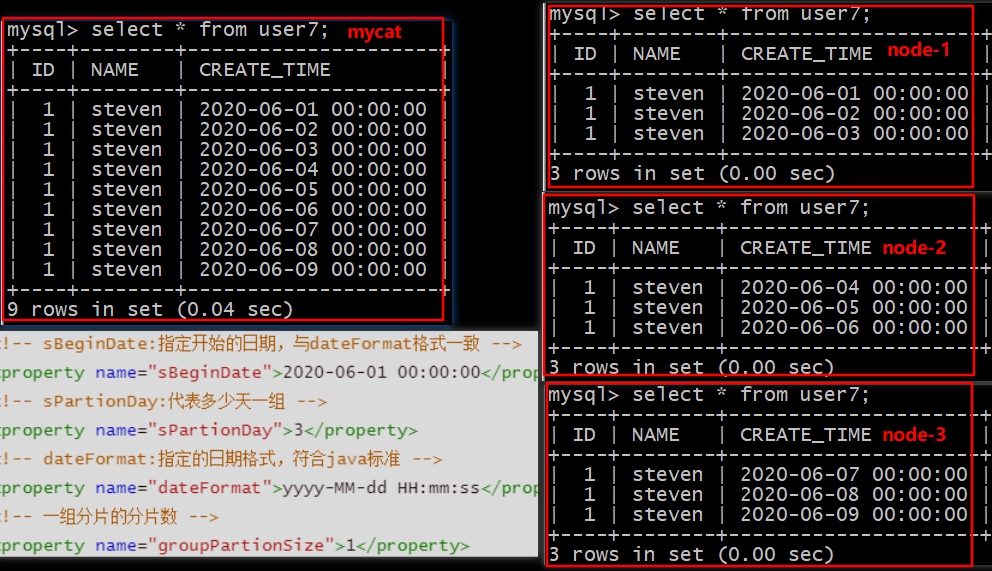
通过结果也可以看出,每三天一个分片,那么我们只有三个数据节点,所以到10号的数据的时候,没有办法进行数据的插入了,原因就在于没有足够多的数据节点。
insert into user7(id,name,create_time) values(1,’steven’,’2020-06-11 00:00:00’);ERROR 1064 (HY000): Can’t find a valid data node for specified node index :USER7 -> CREATE_TIME -> 2020-06-10 00:00:00 -> Index : 3
2.13、冷热数据分片
根据日期查询冷热数据分布,最近n个月的到实时交易库查询,其他的到其他库中
修改schema.xml文件
1 | <table name="user8" dataNode="dn1,dn2,dn3" rule="sharding-by-hotdate" /> |
修改rule.xml文件
1 | <tableRule name="sharding-by-hotdate"> |
重启mycat
建表
1 | CREATE TABLE user8(create_time timestamp NULL ON UPDATE CURRENT_TIMESTAMP ,`db_nm` varchar(20) NULL); |
插入数据
1 | INSERT INTO user8 (create_time,db_nm) VALUES ('2021-03-01', database()); |
查询结果
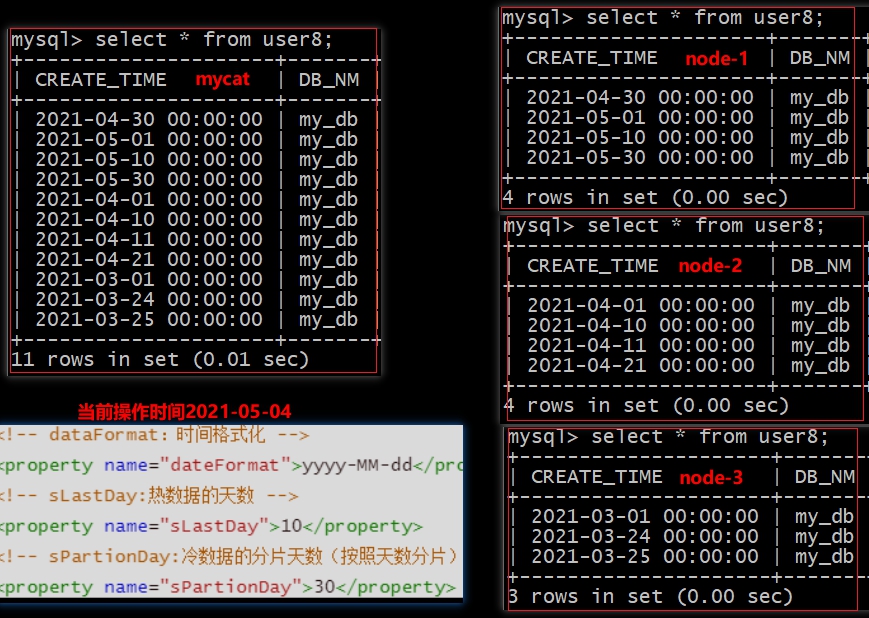
当前时间之后及前
sLastDay天的数据放入第一个节点当前操作时间前
sPartionDay-当前操作时间前sLastDay天内的数据放入第二个节点其余当如第三个节点
2.14、自然月分片
修改schema.xml文件
1 | <table name="user9" dataNode="dn1,dn2,dn3" rule="sharding-by-month" /> |
修改rule.xml文件
1 | <tableRule name="sharding-by-month"> |
重启mycat
建表
1 | CREATE TABLE user9(id int,name varchar(10),create_time varchar(20)); |
插入数据
1 | insert into user9(id,name,create_time) values(111,'zhangsan','2021-01-01'); |
查询结果
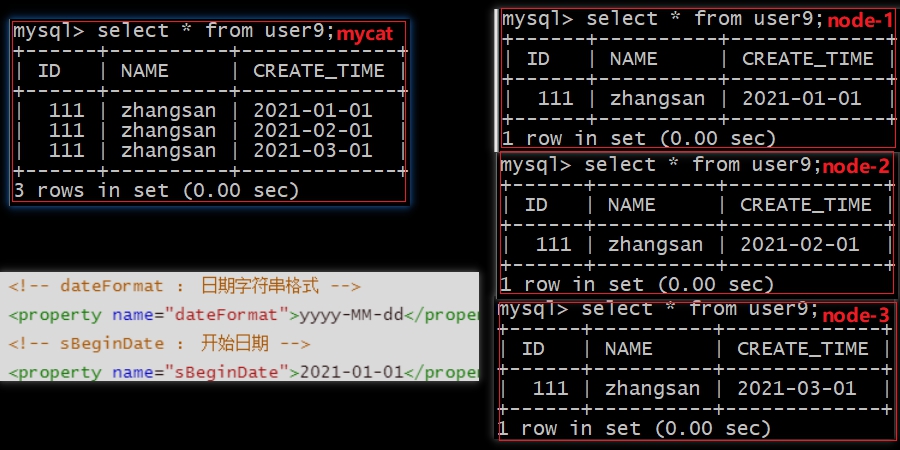
从
sBeginDate指定的月份开始,根据配置的节点数进行分片,因为配置了三个节点,所以如图所示,只有前三个月的数据会被会被分配插入,其余的报错ERROR 1064 (HY000): Can’t find a valid data node for specified node index :USER9 -> CREATE_TIME -> 2021-11-01 -> Index : 10 因为无法找到对应有效的节点
2.15、一致性hash分片
实现方式:一致性hash分片,利用一个分片节点对应一个或者多个虚拟hash桶的思想,尽可能减少分片扩展时的数据迁移。将指定的列值进行hash再对2^32进行取模得到hash环的对应位置
优点:有效解决了分布式数据库的扩容问题。
缺点:在横向扩展的时候,需要迁移部分数据;由于虚拟桶倍数与分片节点数都必须是正整数,而且要服从”虚拟桶倍数×分片节点数=设计极限”,因此在横向扩容的过程中,增加分片节点并不是一台一台地加上去的,而是以一种因式分解的方式增加,因此有浪费物理计算力的可能性。
修改schema.xml文件
1 | <table name="user10" dataNode="dn1,dn2,dn3" primaryKey="id" rule="sharding-by-murmur" /> |
修改rule.xml文件
1 | <tableRule name="sharding-by-murmur"> |
重启mycat
建表
1 | create table user10(id bigint not null primary key,name varchar(20)); |
插入数据
1 | insert into user10(id,name) values(1111111,database()); |
查询结果
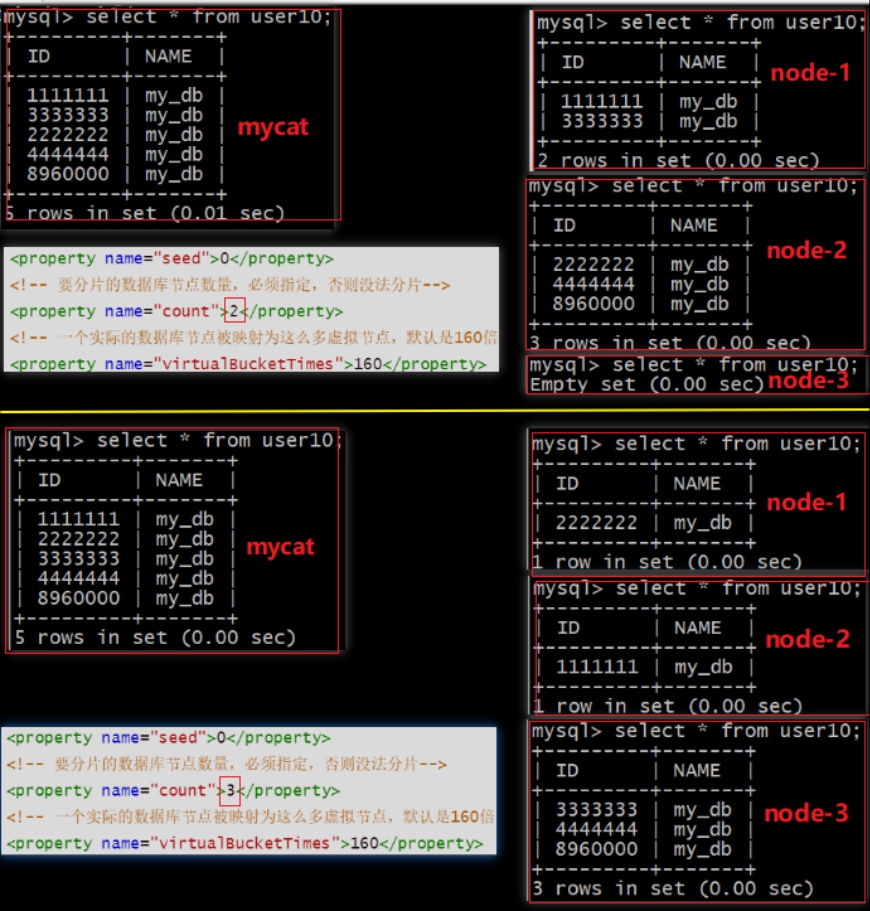
根据
count指定分片的节点数量,每个节点会被映射virtualBucketTimes倍的虚拟节点,将columns字段计算hash值再对2^32取模得出hash槽位,顺时针寻找该位最近的节点进行存储
三、分片join
Join绝对是关系型数据库中最常用的一个特性,然而在分布式环境中,跨分配的join却是最复杂的,最难解决的一个问题。
性能建议:
- 尽量避免使用left join或right join,而用inner join
- 在使用left join或right join时,on会优先执行,where条件在最后执行,所以再使用过程中,条件尽可能的在on语句中判断,减少where的执行
- 少使用子查询,而用join
mycat目前版本支持跨分配的join,主要有四种实现方式:全局表、ER分片、catletT(人工智能)、ShareJoin
全局表
在分片的情况下,当业务表因为规模而进行分片之后,业务表与这个字典表的之间关联会变得比较棘手,因此,在mycat中存在一种全局表,他具备以下特性:
- 全局表的插入、更新操作会实时的在所有节点上执行,保持各个分片的数据一致性
- 全局表的查询操作,只从一个节点获取
- 全局表可以跟任何一个表进行join操作
修改schema.xml文件
1 | <table name="dict_order_type" dataNode="dn1,dn2" type="global"></table> |
重启mycat
建表
1 | CREATE TABLE dict_order_type( |
插入数据
1 | INSERT INTO dict_order_type(id,order_type) VALUES(101,'type1'); |
查询结果

由图可以看出,每个节点都保存了一份数据,而查询只会从一个节点获取,相当于每个节点都冗余了一个全局表,以便节点内的数据join操作
ER分片
在mycat中,我们已经将orders进行了数据分片,但是orders表跟orders_detail发生关联,如果只把orders_detail放到一个分片上,那么跨库的join很麻烦,所以提出了ER关系的表分片。什么意思呢?就是通过关联关系,将子表与父表关联的记录放在同一个数据分片上。
修改schema.xml文件
1 | <table name ="orders" dataNode="dn1,dn2" rule="mod_rule"> |
修改rule.xml文件
1 | <tableRule name="mod_rule"> |
重启mycat
建表
1 | --订单表 |
插入数据
1 | INSERT INTO orders(id,order_type,customer_id,amount) VALUES (1,101,100,100100); |
查询结果

关联关系,将子表与父表关联的记录放在同一个数据分片上,以便数据之间的join关联
Share join
ShareJoin是一个简单的跨分片join,基于HBT的方式实现。目前支持2个表的join,原理是解析SQL语句,拆分成单表的SQL语句执行,然后把各个节点的数据汇集。
修改schema.xml文件
1 | <table name="company" primaryKey="id" dataNode="dn1,dn2,dn3" rule="mod-long" /> |
修改rule.xml文件
1 | <tableRule name="mod-long"> |
修改partition-hash-int.txt文件
1 | 10000=0 |
重启mycat
建表
1 | create table company(id int primary key,name varchar(10)) engine=innodb; |
插入数据
1 | insert company (id,name) values(1,'mycat'); |
查询结果
1 | -- 可以看到有时可以查出对应的结果,有时则查询不到 |
四、全局序列号
1、本地文件方式
使用此方式的时候,mycat讲sequence配置到文件中,当使用到sequence中的配置,mycat会更新sequence_conf.properties文件中sequence当前的值。
配置方式:
在 sequence_conf.properties 文件中做如下配置:
1 | = |
其中 HISIDS 表示使用过的历史分段(一般无特殊需要可不配置), MINID 表示最小 ID 值, MAXID 表示最大
ID 值, CURID 表示当前 ID 值。
server.xml 中配置:
1 | <system><property name="sequnceHandlerType">0</property></system> |
注: sequnceHandlerType 需要配置为 0,表示使用本地文件方式。
案例使用:
1 | create table tab1(id int primary key,name varchar(10)); |
缺点:当mycat重新发布后,配置文件中的sequence会恢复到初始值
优点:本地加载,读取速度较快
2、数据库方式
在数据库中建立一张表,存放sequence名称(name),sequence当前值(current_value),步长(increment int类型,每次读取多少个sequence,假设为K)等信息;
获取数据步骤:
1、当初次使用该sequence时,根据传入的sequence名称,从数据库这张表中读取current_value和increment到mycat中,并将数据库中的current_value设置为原current_value值+increment值。
2、mycat将读取到current_value+increment作为本次要使用的sequence值,下次使用时,自动加1,当使用increment次后,执行步骤1中的操作
3、mycat负责维护这张表,用到哪些sequence,只需要在这张表中插入一条记录即可,若某次读取的sequence没有用完,系统就停掉了,则这次读取的sequence剩余值不会再使用
配置方式:
1、修改server.xml文件
1 | <system><property name="sequnceHandlerType">1</property></system> |
2、修改schema.xml文件
1 | <table name="test" primaryKey="id" autoIncrement="true" dataNode="dn1,dn2,dn3" rule="mod-long"/> |
3、修改mycat配置文件sequence_db_conf.properties,添加属性值
1 | #sequence stored in datanode |
4、在dn2上添加mycat_sequence表
1 | DROP TABLE IF EXISTS mycat_sequence; |
5、在dn2上的mycat_sequence表中插入初始记录
1 | INSERT INTO mycat_sequence(name,current_value,increment) VALUES ('mycat', -99, 100); |
6、在dn2上创建函数
1 | --创建函数 |
数据测试:
1、插入数据表
1 | create table test(id int,name varchar(10)); |
2、查询对应的序列数据表
1 | SELECT * FROM mycat_sequence; |
3、向表中插入数据,可以多执行几次
1 | insert into test(id,name) values(next value for MYCATSEQ_MYCAT,(select database())); |
4、查询添加的数据
1 | SELECT * FROM test order by id asc; |
5、重新启动mycat,重新添加数据,查看结果,重启之后从101开始
1 | SELECT * FROM mycat_sequence; |
6、重新查询数据表test
1 | SELECT * FROM test order by id asc; |
大家在使用的时候会发现报错的情况,这个错误的原因不是因为我们的配置,是因为我们的版本问题,简单替换下版本即可。
1 | mysql> insert into test(id,name) values(next value for MYCATSEQ_MYCAT,(select database())); |
3、本地时间戳方式
ID= 64 位二进制 (42(毫秒)+5(机器 ID)+5(业务编码)+12(重复累加)。
换算成十进制为 18 位数的 long 类型,每毫秒可以并发 12 位二进制的累加。
使用方式:
1、配置server.xml文件
1 | <property name="sequnceHandlerType">2</property> |
2、修改sequence_time_conf.properties
1 | WORKID=06 #任意整数 |
3、修改schema.xml文件
1 | <table name="test2" dataNode="dn1,dn2,dn3" primaryKey="id" autoIncrement="true" rule="mod-long" /> |
4、启动mycat,并且创建表进行测试
1 | create table test2(id bigint auto_increment primary key,xm varchar(32)); |
此方式的优点是配置简单,但是缺点也很明显就是18位的id太长,需要耗费多余的存储空间。
4、自定义全局序列
用户还可以在程序中自定义全局序列,通过java代码来实现,这种方式一般比较麻烦,因此在能使用mycat提供的方式满足需求的前提下一般不需要自己通过java代码来实现。
5、分布式ZK ID生成器
如果在搭建的时候使用了zookeeper,也可以使用zk来生成对应的id,此方式需要zk的配合,此处不再展示,有兴趣的同学下去自己演示即可。