一、概念
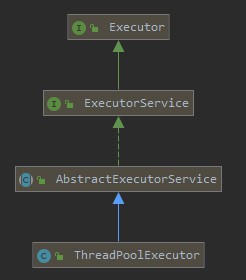
Java中的线程池核心实现类是ThreadPoolExecutor。
顶级接口Executor
- 顶层接口
Executor提供了一种思想:将任务提交和任务执行进行解耦。 - 用户无需关注如何创建线程,如何调度线程来执行任务,用户只需提供
Runnable对象,将任务的运行逻辑提交到执行器(Executor)中,由Executor框架完成线程的调配和任务的执行部分。
接口ExecutorService
接口增加了一些能力:
- 扩充执行任务的能力,补充可以为一个或一批异步任务生成Future的方法。
- 提供了管控线程池的方法,比如停止线程池的运行。
抽象类AbstractExecutorService
上层的抽象类:
- 将执行任务的流程串联了起来,保证下层的实现只需关注一个执行任务的方法即可。
实现类ThreadPoolExecutor
实现最复杂的运行部分:
- ThreadPoolExecutor将会一方面维护自身的生命周期。
- 另一方面同时管理线程和任务,使两者良好的结合从而执行并行任务。
模型
线程池在内部实际上构建了一个生产者消费者模型,将线程和任务两者解耦,并不直接关联,从而良好的缓冲任务,复用线程。
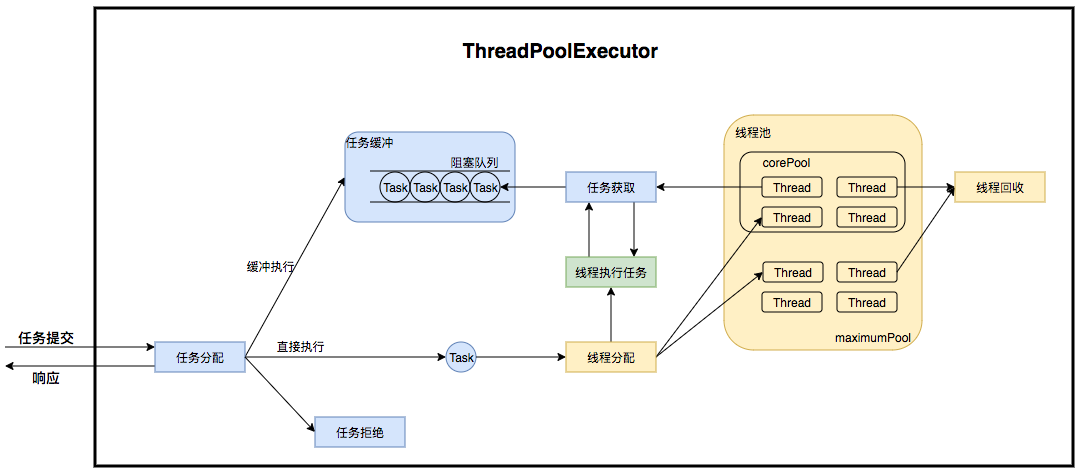
线程池的运行主要分成两部分:任务管理、线程管理。
生产者
任务管理部分充当生产者的角色,当任务提交后,线程池会判断该任务后续的流转:
- (1)直接申请线程执行该任务;
- (2)缓冲到队列中等待线程执行;
- (3)拒绝该任务。
消费者
线程管理部分是消费者,它们被统一维护在线程池内,根据任务请求进行线程的分配,当线程执行完任务后则会继续获取新的任务去执行,最终当线程获取不到任务的时候,线程就会被回收。
二、生命周期
线程池运行的状态,并不是用户显式设置的,而是伴随着线程池的运行,由内部来维护。
线程池内部使用变量ctl来维护两个值:runState(运行状态,使用ctl的高3位来维护)、workerCount(线程数量,使用ctl的低29位来维护)。
1 | private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0)); |
用一个变量去存储两个值,可避免在做相关决策时,出现不一致的情况,不必为了维护两者的一致,而占用锁资源。
关于内部封装的获取生命周期状态、获取线程池线程数量,ThreadPoolExecutor提供了如下变量和方法以供操作:
1 | //Integer.SIZE = 32 |
runState
标识线程池运行状态,使用ctl变量的高3位来保存。
runState提供主要的生命周期控制,主要状态如下:
| 运行状态 | 数值 | 状态描述 |
|---|---|---|
| 运行(RUNNING) | -1 << 29 | 能接受新任务,并处理排队的任务 |
| 关机(SHUTDOWN) | 0 << 29 | 不接受新任务,但可以继续处理队列中的任务 |
| 停止(STOP) | 1 << 29 | 不接受新任务,也不会处理排队的任务,并且中断正在进行的任务 |
| 整理(TIDYING) | 2 << 29 | 所有任务已终止,workerCount为零,线程转换为TIDYING状态之后将运行terminate()方法(钩子方法) |
| 终止(TERMINATED) | 3 << 29 | 在terminated()方法执行,进入此状态,在awaitTermination()中等待的线程将返回 |
以上的状态是数值有序的,可以进行有序的比较,RUNNING最小,TERMINATED最大,但不必达到每个状态,变化如下图:
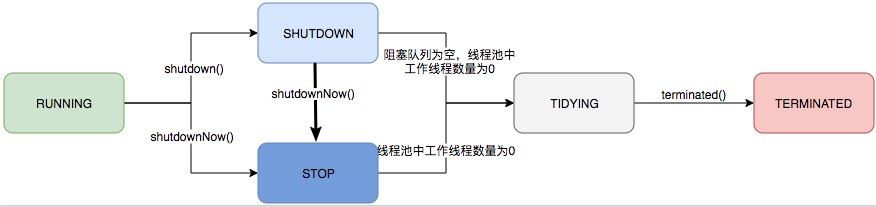
1、RUNNING -> SHUTDOWN:在调用shutdown()时,可能隐式在finalize()中使用
2、(RUNNING or SHUTDOWN) -> STOP:在调用shutdownNow()时
3、SHUTDOWN -> TIDYING:当队列和有效工作线程都为空时
4、STOP -> TIDYING:有效工作线程都为空时
5、TIDYING -> TERMINATED:当terminate()调用完成时
workerCount
指线程池当前工作的有效线程数,使用ctl变量的低29位保存。所以workerCount限制约为5亿(2 ^ 29-1)个线程。
三、执行流程
1、任务调度
所有任务的调度都是由execute方法完成的,这部分完成的工作是:检查现在线程池的运行状态、运行线程数、运行策略,决定接下来执行的流程,是直接申请线程执行,或是缓冲到队列中执行,亦或是直接拒绝该任务。其执行过程如下:
- 首先检测线程池运行状态,如果不是RUNNING,则直接拒绝,线程池要保证在RUNNING的状态下执行任务。
- 如果workerCount < corePoolSize,则创建并启动一个线程来执行新提交的任务。
- 如果workerCount >= corePoolSize,且线程池内的阻塞队列未满,则将任务添加到该阻塞队列中。
- 如果workerCount >= corePoolSize && workerCount < maximumPoolSize,且线程池内的阻塞队列已满,则创建并启动一个线程来执行新提交的任务。
- 如果workerCount >= maximumPoolSize,并且线程池内的阻塞队列已满, 则根据拒绝策略来处理该任务, 默认的处理方式是直接抛异常。

2、任务申请
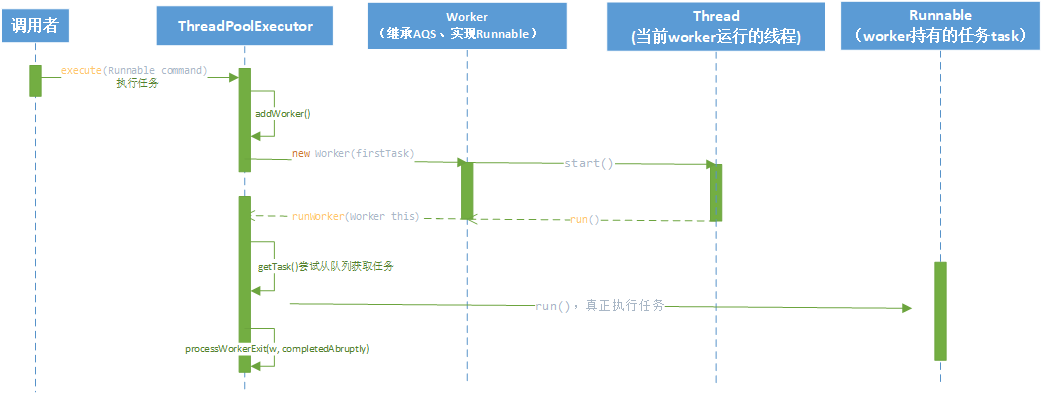
execute-提交Runnable任务
调用ThreadPoolExecutor的execute(Runnable command)方法提交任务到线程池,方法如下:
1 | public void execute(Runnable command) { |
当前工作线程数 < 核心线程数
创建核心线程并执行任务
工作线程数 >= 核心线程数
线程池处于运行状态 && 任务放入队列成功
线程池不是运行状态并且队列移除任务成功
执行拒绝策略
线程池为运行状态 且 线程池不是运行状态但队列移除任务失败 且 当前工作线程数量为空
创建当前任务为空的非核心线程,空任务的work会去队列获取任务并执行
线程池非运行状态 || 队列满了
尝试创建非核心线程并执行任务,失败则执行拒绝策略
submit-提交Callable任务
1 | //该方法为抽象父类AbstractExecutorService的实现方法 |
submit可以提交callable任务,callable任务可以获取线程执行的返回结果
通过newTaskFor(task)方法创建FutureTask(Runnable实现类)交给execute(ftask)方法执行
FutureTask
实现RunnableFuture 接口,RunnableFuture 接口继承了Runnable,和Future ;因此给交给execute执行
addWorker-创建线程执行任务
| 重载方法 | 描述 | execute()方法中触发条件 |
|---|---|---|
| addWorker(command, true) | 创建核心线程,执行任务 | 1.当前工作线程数 < 核心线程数 |
| addWorker(command, false) | 创建非核心线程,执行任务 | 1.工作线程数 >= 核心线程数 2.且 线程池非运行状态 || 队列满了 |
| addWorker(null, false) | 创建非核心线程,当前任务为空 | 1.线程池为运行状态 或者 (线程池不是运行状态但队列移除任务失败) 2.当前工作线程数量为空 |
此方法较长需要分成两部分来分析:
1 | private boolean addWorker(Runnable firstTask, boolean core) { |
第一部分:循环使用CAS、重读ctl等操作,判断是否可以
创建worker,失败则返回false跳出此方法,成功则跳出循环执行第二部分代码第二部分:加锁同步
创建work并启动执行任务
work-工作线程
线程池为了掌握线程的状态并维护线程的生命周期,设计了线程池内的工作线程Worker,其为ThreadPoolExecutor的私有内部类。
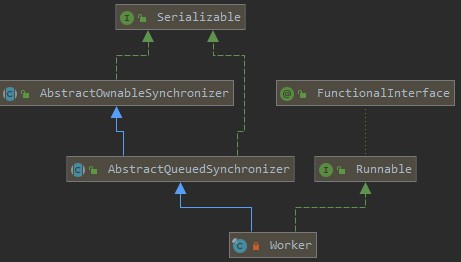
1 | private final class Worker extends AbstractQueuedSynchronizer implements Runnable{ |
Worker实现了Runnable接口,并持有一个线程thread,一个初始化的任务firstTask。
thread是在调用构造方法时通过ThreadFactory来创建的线程,可以用来执行任务;firstTask用它来保存传入的第一个任务,这个任务可以有,也可以为null。firstTask非空,那么线程就会在启动初期立即执行这个任务,也就对应核心线程创建时的情况;firstTask为null,那么就需要创建一个线程去执行任务队列(workQueue)中的任务,也就是非核心线程的创建。
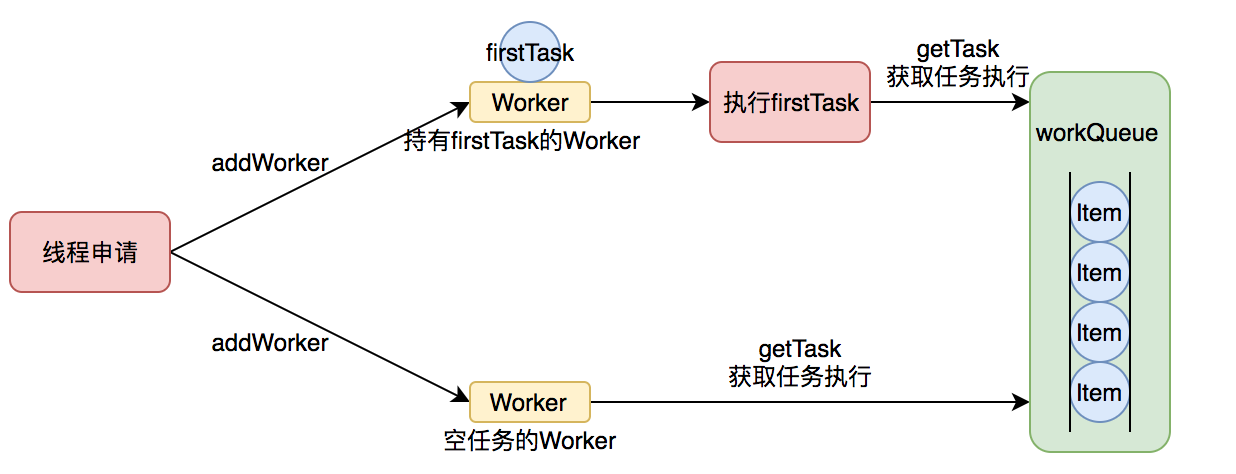
runWorker-真正执行任务
流程
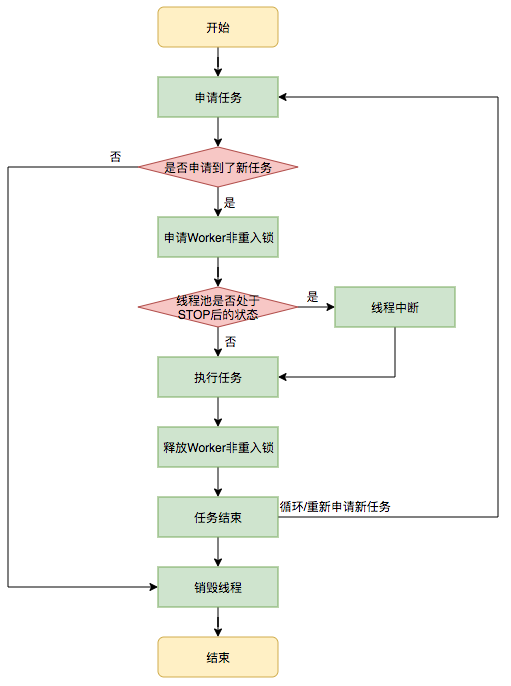
当 worker.thread.start()调用work的run(),该方法调用了runWorker(this)去真正执行任务
- while循环不断地通过getTask()方法获取任务。
- getTask()方法从阻塞队列中取任务。
- 如果线程池正在停止,那么要保证当前线程是中断状态,否则要保证当前线程不是中断状态。
- 执行任务。
- 如果getTask结果为null则跳出循环,执行processWorkerExit()方法,销毁线程。
源码分析
1 | final void runWorker(Worker w) { |
1.首先尝试执行
firstTask,若没有的话,则调用getTask()从队列中获取任务
2.加锁
3.如果线程池非运行状态,中断当前线程
4.调用beforeExecute(wt, task)前置处理方法
5.执行任务调用task.run()
6.调用afterExecute(task, thrown)后置处理方法
7.累加该worker的completedTasks(完成任务数)
8.解锁
9.异常或者获取不到任务时,调用processWorkerExit(w, completedAbruptly)处理worker
getTask()-从队列中获取任务
runWorker()的主要任务就是一直loop循环,来一个任务处理一个任务,没有任务就去getTask(),getTask()可能会阻塞
1 | private Runnable getTask() { |
判断线程池是否为运行状态,不是的话cas减少工作线程数,返回退出方法
判断满足以下任一条件则减少工作线程后退出方法,否则重试
工作线程数量 > 最大线程数 并且 工作线程数量大于1
工作线程数量 > 最大线程数 并且 工作队列为空
允许核心线程超时 并且 上一次队列的poll()方法超时 并且 工作线程数量大于1
允许核心线程超时 并且 上一次队列的poll()方法超时 并且 工作队列为空(允许核心线程超时 || 工作线程数量 > 核心线程数)使用超时等待方法workQueue.poll(),移除获取,没有值为null;否则使用workQueue.take()为空时阻塞等待获取
processWorkerExit()-处理异常或者无任务执行的worker
当runWorker()的获取不到任务或者出现异常时,会调用processWorkerExit(w, completedAbruptly)方法
1 | private void processWorkerExit(Worker w, boolean completedAbruptly) { |
减少工作线程数量,移除该worker,如果当前线程池仍然是运行中的状态
1。当此方法为非异常调用时
当允许核心线程超时时,worker(工作线程)数量 >= 1时,直接返回,无需创建新的worker
当核心线程不允许超时时,worker(工作线程)数量 >= 核心线程数,直接返回,无需创建新的worker
其余情况创建新worker替代旧worker
2.当此方法为异常调用时
创建新worker替代旧worker
3、线程管理
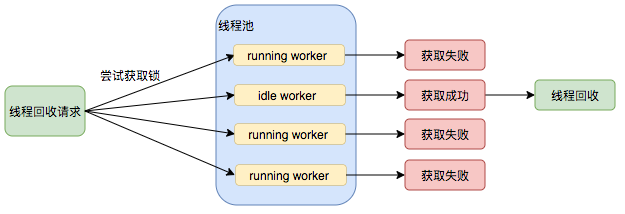
线程池需要管理线程的生命周期,需要在线程长时间不运行的时候进行回收。线程池使用HashSet来维持对线程的引用,这样可以通过添加引用、移除引用这样的操作来控制线程的生命周期。这个时候重要的就是如何判断线程是否在运行。
Worker是通过继承AQS,使用AQS来实现独占锁这个功能。没有使用可重入锁ReentrantLock,而是使用AQS,为的就是实现不可重入的特性去反应线程现在的执行状态。
- lock方法一旦获取了独占锁,表示当前线程正在执行任务中。
- 如果正在执行任务,则不应该中断线程。
- 如果该线程现在不是独占锁的状态,也就是空闲的状态,说明它没有在处理任务,这时可以对该线程进行中断。
- 线程池在执行shutdown方法或tryTerminate方法时会调用interruptIdleWorkers方法来中断空闲的线程,interruptIdleWorkers方法会使用tryLock方法来判断线程池中的线程是否是空闲状态;如果线程是空闲状态则可以安全回收。