底层原理
正排索引(doc values )VS 倒排索引
概念:从广义来说,正排索引(doc values ) 本质上是一个序列化的列式存储。列式存储 适用于聚合、排序、脚本等操作,所有的数字、地理坐标、日期、IP 和不分析( not_analyzed )字符类型都会默认开启。
而倒排索引的优势在于查找包含某个项的文档,相反,也可以用它确定哪些项是否存在单个文档里。
优化:es官方是建议,es大量是基于os cache来进行缓存和提升性能的,不建议用jvm内存来进行缓存,那样会导致一定的gc开销和oom问题,给jvm更少的内存,给os cache更大的内存。比如64g服务器,给jvm最多4 ~ 16g(1/16 ~ 1/4),os cache可以提升doc value和倒排索引的缓存和查询效率。
总结:全文搜索需要用倒排索引,而排序和聚合则需要使用 正排索引。
在Mappings中有两个相关配置
doc_values:true/false
为该字段创建正排索引,默认true,不支持text类型(不分词的field默认true,text类型为false)
提升聚合统计性能,为false时可以节省磁盘空间,但当需要使用聚合操作,需要将fielddata设置为true,可以在内存中创建临时的正排索引
index:true/false
为该字段创建倒排索引,默认为true
1 | PUT /product |
1 | //当使用es自带的keyword时,它字段值是一个整体的精确匹配,并不会对字段值的内容进行分词 |
而
doc_values正排索引不支持text字段,那text字段怎么进行聚合操作呢?
1 | //当直接使用tags进行聚合操作,想要聚合tags中的分词后的terms词项,会报错 |
1 | Text fields are not optimised for operations that require per-document field data like aggregations and sorting, |
大概的意思是,必须要打开fielddata=true,然后将正排索引数据加载到内存中,才可以对分词的field执行聚合操作,而且会消耗很大的内存。
1 | //修改Mapping结构:开启tags字段 在使用聚合操作时使用 正排索引进行计算 |
这时候再次执行上文的tags的聚合操作,就不会报错了,那么fielddata和doc_values都是开启正排索引,他们之间有什么区别呢?
| 维度 | doc_values | fielddata |
|---|---|---|
| 创建时间 | index时创建 | 使用时动态创建 |
| 创建位置 | 磁盘 | 内存(jvm heap) |
| 优点 | 不占用内存空间 | 不占用磁盘空间 |
| 缺点 | 索引速度稍低 | 文档很多时,动态创建开销比较大,而且占内存 |
| 默认值 | true | false |
doc_values速度稍低,这个是相对于fielddata方案的,其实仔细想想也可以理解。拿排序举例,相对于一个在磁盘排序,一个在内存排序。谁的速度快自然不用多说。
与 doc values 不同,fielddata 构建和管理 100% 在内存中,常驻于 JVM 内存堆。这意味着它本质上是不可扩展的。
fielddata可能会消耗大量的堆空间,尤其是在加载高基数(high cardinality)text字段时。一旦fielddata已加载到堆中,它将在该段的生命周期内保留。此外,加载fielddata是一个昂贵的过程,可能会导致用户遇到延迟命中。这就是默认情况下禁用fielddata的原因。
doc_values虽然速度稍慢,但doc_values的优势还是非常明显的。一个很显著的点就是他不会随着文档的增多引起OOM问题。正如前面说的,doc_values在磁盘创建排序和聚合所需的正排索引。这样我们就避免了在生产环境给ES设置一个很大的HEAP_SIZE,也使得JVM的GC更加高效,这个又为其它的操作带来了间接的好处。
1 | 1.当没有文档的value字段需要聚合,而doc_values为false时,需要打开fielddata,然后临时在内存中建立正排索引,fielddata的构建和管理发生在JVM heap中。 |
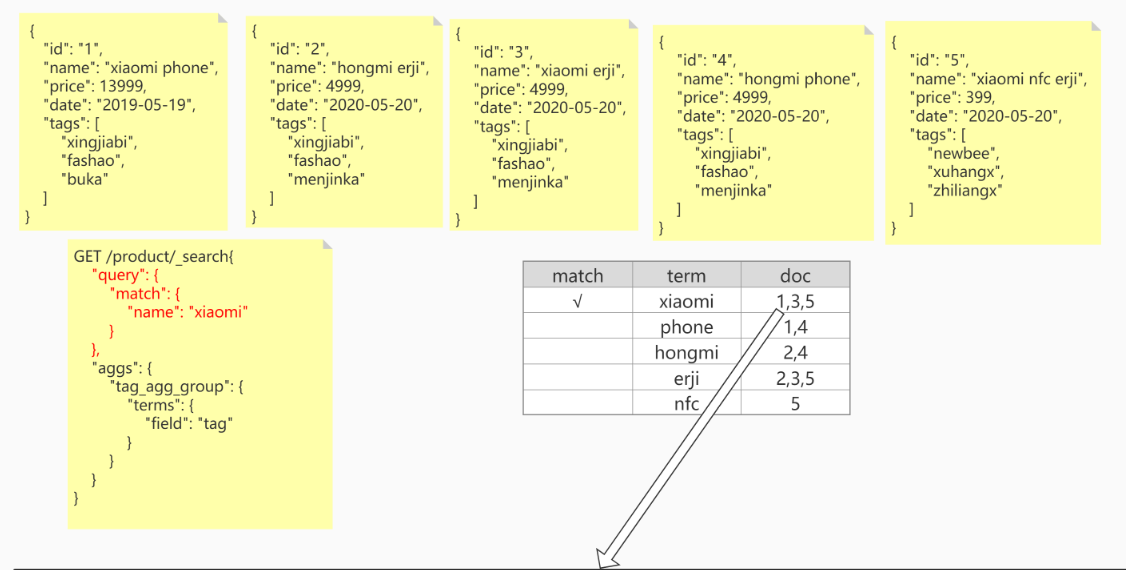
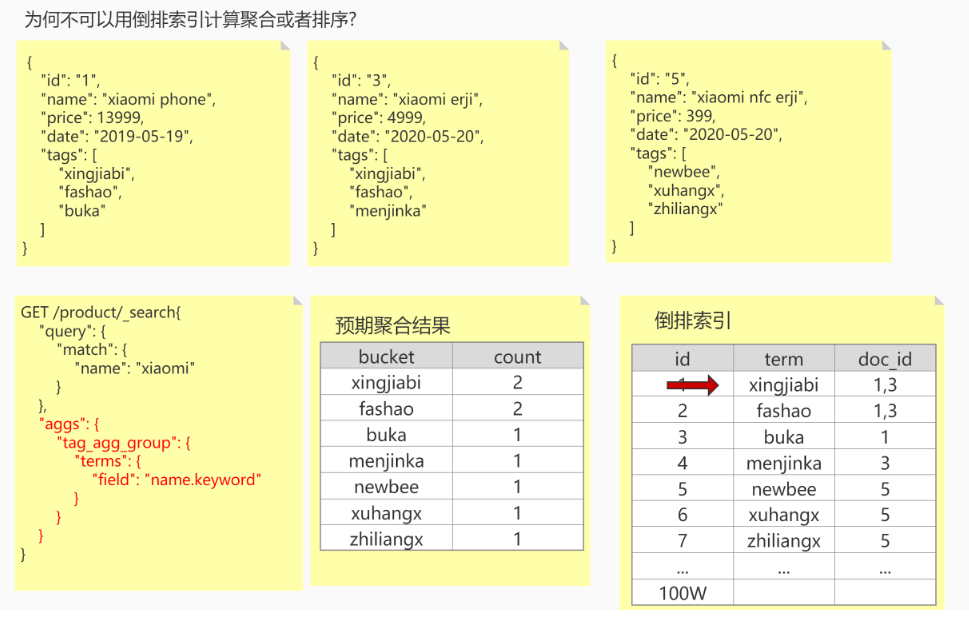
为什么不可以用倒排索引计算聚合?
对于聚合部分,我们需要找到匹配的doc里所有唯一的词项(term)。需要遍历每个doc获取所有trem词项,然后再一个个去倒排索引表中进行查找,是一个 n x m 的操作,做这件事情性能很低,很有可能会造成全表遍历。
因此通过正排索引来解决聚合问题。

操作原理
读操作
1 | 搜索被执行成一个两阶段过程,称为 Query Then Fetch; |
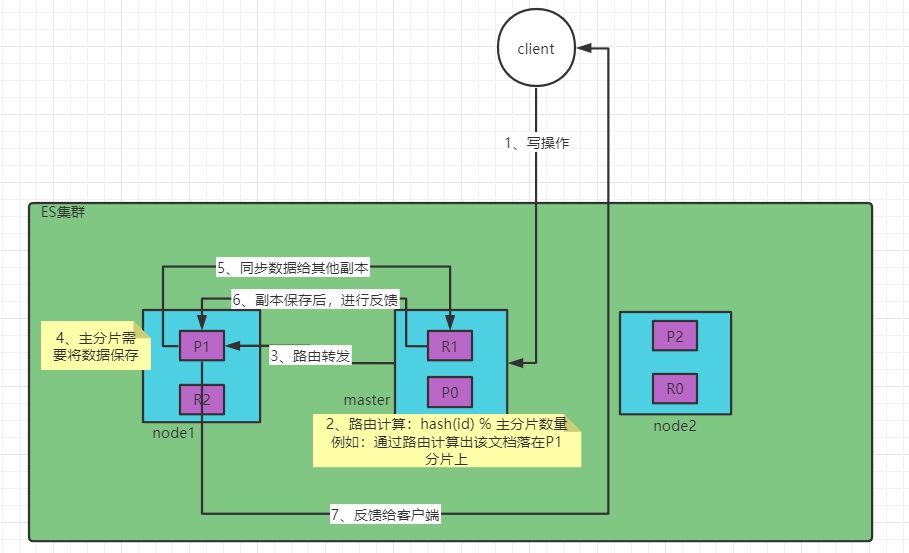
写操作
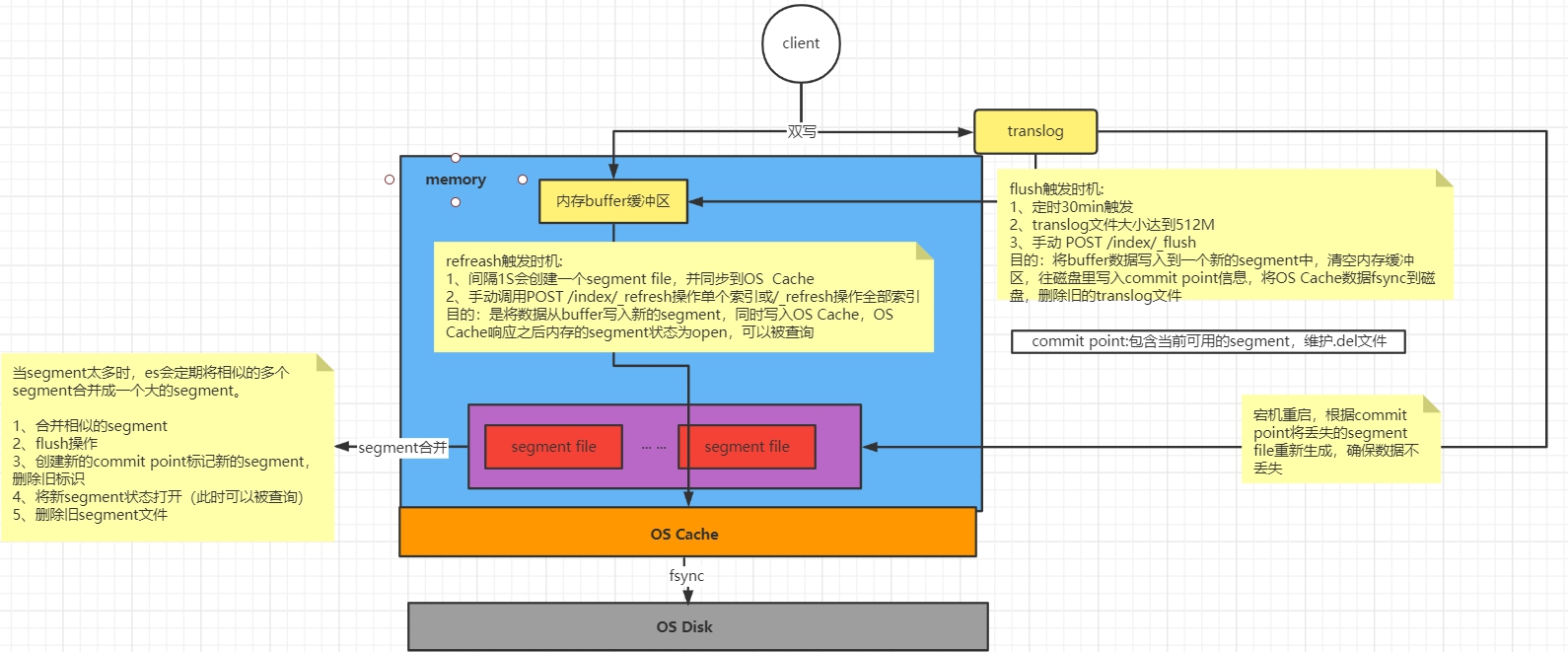
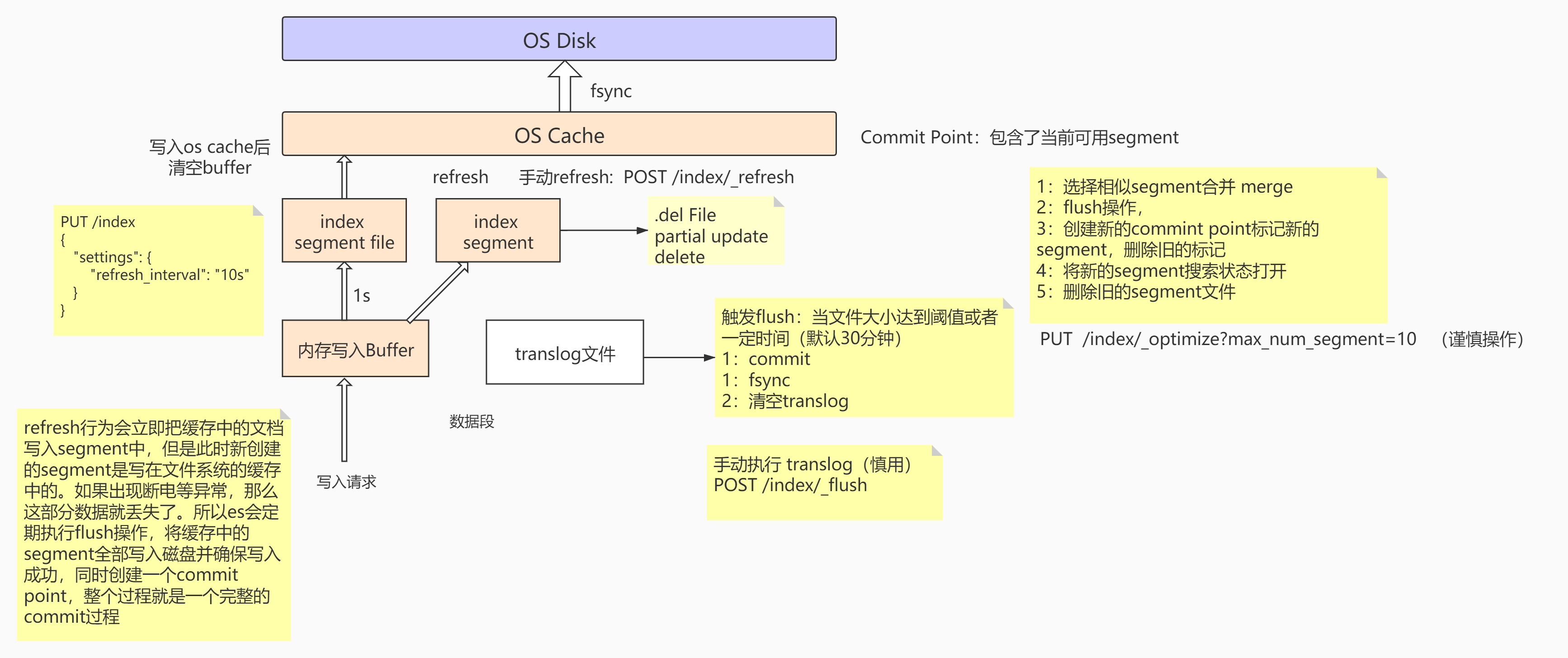
当有写入请求时,数据会先写到内存的Buffer中(Buffer专门用于写入操作,默认占jvm的10%),每间隔1S会创建一个index segment的file,然后segment会同步到OS cache中,OS cache会返回一个status = Open,这时候的segment就能对外提供搜索操作。
读写操作进行了异步分离操作,segment对外提供读搜索操作,OS cache后台异步写入数据。
在这种方式下,如果宕机会造成少部分数据的丢失,ES是怎么避免的?
ES在写入索引时,并没有实时落盘到索引文件,而是先双写到内存和translog文件,假如节点挂了,重启节点时就会重放日志,这样相当于把用户的操作模拟了一遍。保证了数据的不丢失。
1 | 当OS cache中的数据达到一定大小之后或者一定时间后,触发Flush: |
Commit Point用于存储可用的segment,每当创建一个segment时,都会往Commit point中做登记,segment文件并不是无限制地创建的,当达到一定的操作/大小时,会执行segment合并操作:
1 | 1.选择一些体积小的segment,然后将其合并成一个更大的segment |
segment维护了一个.del的文件,当有数据执行删除/更新操作时,它会先将数据在segment中标记成删除的状态,这时候没有物理删除,然后在查询的时候,会将删除状态的数据进行过滤。