Analysis
1
2
3
4
5
6
7
8
9
10
11
12
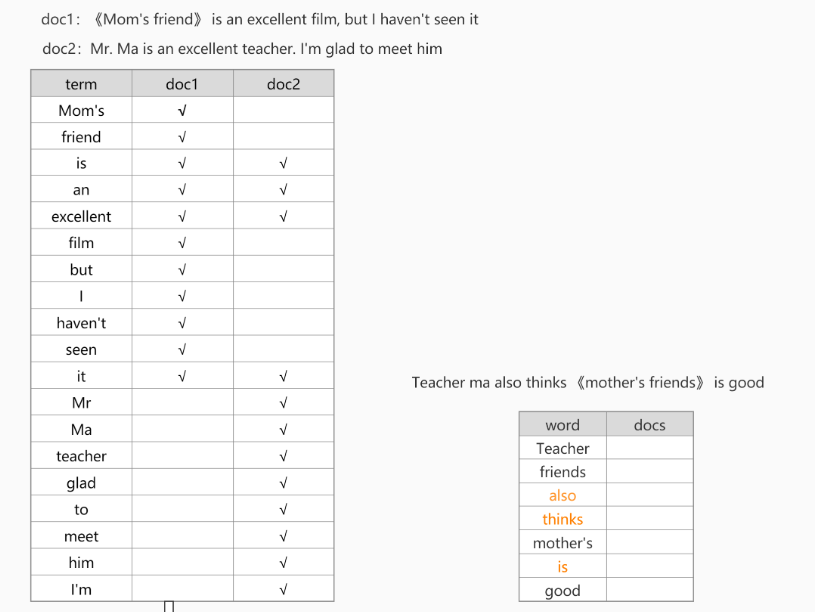
| 分析器:
1.character filter(mapping):分词之前预处理(过滤无用字符、标签等,转换一些&=>and 《es》=> es
HTML Strip Character Filter:html_strip 自动过滤html标签
参数:escaped_tags 需要保留的html标签
Mapping Character Filter:type mapping
Pattern Replace Character Filter:type pattern_replace
4.tokenizer(分词器):分词
5.token filter:停用词、时态转换、大小写转换、同义词转换、语气词处理等。如:has=>have him=>he apples=>apple
|
normalization
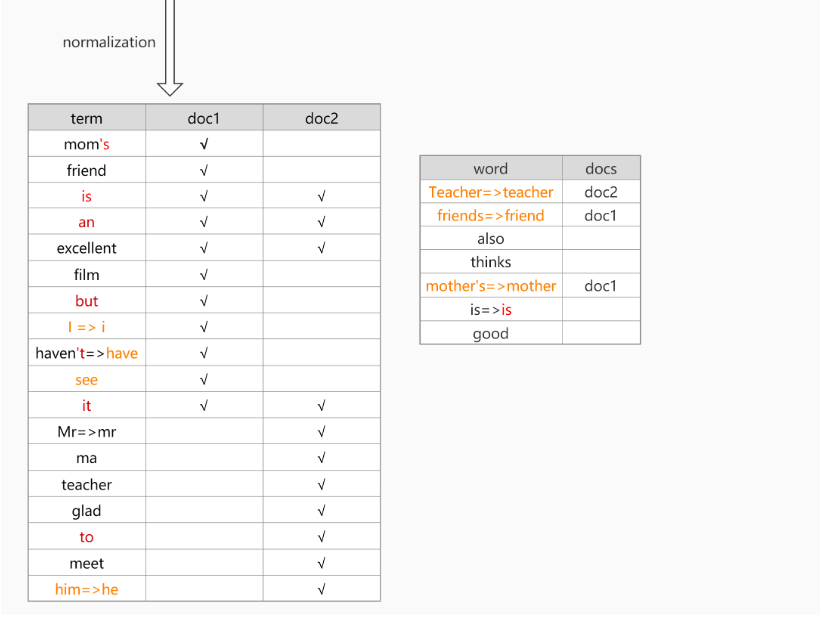
标准化处理是用于完善分词器结果的,提升recall召回率。
character filter
HTML Strip Character Filter
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
PUT my_index
{
"settings": {
"analysis": {
"char_filter": {
"my_char_filter": {
"type": "html_strip",
"escaped_tags": ["a"]
}
},
"analyzer": {
"my_analyzer": {
"tokenizer": "keyword",
"char_filter": ["my_char_filter"]
}
}
}
}
}
|
1
2
3
4
5
6
7
8
9
10
11
|
POST my_index/_analyze
{
"analyzer": "my_analyzer",
"text": "<p>I'm so <a>happy</a>!</p>"
}
输出结果:
"token" : """
I'm so <a>happy</a>!
"""
|
Mapping Character Filter
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "keyword",
"char_filter": [
"my_char_filter"
]
}
},
"char_filter": {
"my_char_filter": {
"type": "mapping",
"mappings": [
"٠ => 0",
"١ => 1",
"٢ => 2",
"٣ => 3",
"٤ => 4",
"٥ => 5",
"٦ => 6",
"٧ => 7",
"٨ => 8",
"٩ => 9"
]
}
}
}
}
}
|
1
2
3
4
5
6
7
8
| POST my_index/_analyze
{
"analyzer": "my_analyzer",
"text": "My license plate is ٢٥٠١٥"
}
输出结果:
"token" : "My license plate is 25015"
|
Pattern Replace Character Filter
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
PUT my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "standard",
"char_filter": ["my_char_filter"]
}
},
"char_filter": {
"my_char_filter": {
"type": "pattern_replace",
"pattern": "(\\d+)-(?=\\d)",
"replacement": "$1_"
}
}
}
}
}
|
1
2
3
4
5
6
7
8
| POST my_index/_analyze
{
"analyzer": "my_analyzer",
"text": "My credit card is 123-456-789"
}
输出结果:
"token" : "My credit card is 123_456_789"
|
token filter
lowercase token filter
1
2
3
4
5
6
7
8
9
10
|
GET _analyze
{
"tokenizer" : "standard",
"filter" : ["lowercase"],
"text" : "THE Quick FoX JUMPs"
}
输出结果:
the、quick、fox、jumps
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
GET /_analyze
{
"tokenizer": "standard",
"filter": [
{
"type": "condition",
"filter": [ "lowercase" ],
"script": {
"source": "token.getTerm().length() < 5"
}
}
],
"text": "THE QUICK BROWN FOX"
}
输出结果:
the、QUICK、BROWN、fox
|
stopwords token filter
在信息检索中,停用词是为节省存储空间和提高搜索效率,处理文本时自动过滤掉某些字或词,这些字或词即被称为Stop Words(停用词)。
停用词大致分为两类。一类是语言中的功能词,这些词极其普遍而无实际含义,如“the”、“is“、“which“、“on”等。另一类是词汇词,比如’want’等,这些词应用广泛,但搜索引擎无法保证能够给出真正相关的搜索结果,难以缩小搜索范围,还会降低搜索效率。
实践中,通过配置stopwords使得这些词汇不添加进倒排索引中,从而节省索引的存储空间、提高搜索性能。
1
2
3
4
5
6
7
8
9
10
11
12
13
| PUT /my_index
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer":{
"type":"standard",
"stopwords":"_english_"
}
}
}
}
}
|
1
2
3
4
5
6
7
8
9
10
11
| GET my_index/_analyze
{
"analyzer": "my_analyzer",
"text": "Teacher Ma is in the restroom"
}
未启用英语停用词结果:
Teacher、Ma、is、in、the、restroom
启用英语停用词结果:
Teacher、Ma、restroom
|
tokenizer
基于ES 7.6版本,支持的内置分词器有15种。官网介绍
1
2
3
4
5
6
7
8
| 1.standard analyzer:默认分词器,中文支持的不理想,会逐字拆分。
max_token_length:最大令牌长度。如果看到令牌超过此长度,则将其max_token_length间隔分割。默认为255。
2.Pattern Tokenizer:以正则匹配分隔符,把文本拆分成若干词项。
3.Simple Pattern Tokenizer:以正则匹配词项,速度比Pattern Tokenizer快。
4.whitespace analyzer:以空白符分隔 Tim_cookie
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
PUT /test_analysis/
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer":"whitespace"
}
}
}
}
}
|
1
2
3
4
5
6
|
GET /test_analysis/_analyze
{
"analyzer": "my_analyzer",
"text": "ooo is bbbb!!"
}
|
自定义 analysis
设置"type": "custom"告诉Elasticsearch我们正在定义一个定制分析器。将此与配置内置分析器的方式进行比较: type将设置为内置分析器的名称,如 standard或simple
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| PUT /test_analysis
{
"settings": {
"analysis": {
"char_filter": {
"test_char_filter": {
"type": "mapping",
"mappings": [
"& => and",
"| => or"
]
}
},
"filter": {
"test_stopwords": {
"type": "stop",
"stopwords": ["is","in","at","the","a","for"]
}
},
"tokenizer": {
"punctuation": {
"type": "pattern",
"pattern": "[ .,!?]"
}
},
"analyzer": {
"my_analyzer": {
"type": "custom",
"char_filter": [
"html_strip",
"test_char_filter"
],
"tokenizer": "standard",
"filter": ["lowercase","test_stopwords"]
}
}
}
}
}
|
1
2
3
4
5
6
7
8
| GET /test_analysis/_analyze
{
"text": "Teacher ma & zhang also thinks [mother's friends] is good | nice!!!",
"analyzer": "my_analyzer"
}
分词结果:
teacher、ma、and、zhang、also、thinks、mother's、friends、good、or、nice
|
IK中文分词器
IK分词器下载地址
1
2
3
4
5
| IK分词器安装步骤:
1.上Github下载IK分词器
2.解压分词器,使用maven进行package打包
3.从releases中获取打好的zip包,放到es安装目录/plugins/ik/ 目录下解压
4.重启ES
|
如果ES版本比IK分词器版本高,启动ES时可能会出现如下错误:
1
| Plugin [analysis-ik] was built for Elasticsearch version 7.4.0 but version 7.10.1 is running
|
需要修改IK分词器的配置文件plugin-descriptor.properties:
1
2
|
elasticsearch.version=7.10.1
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| IK分词器提供两种analyzer
ik_max_word:细粒度
ik_smart:粗粒度
2.IK文件描述
IKAnalyzer.cfg.xml:IK分词配置文件
主词库:main.dic
英文停用词:stopword.dic,不会建立在倒排索引中
特殊词库:
quantifier.dic:特殊词库:计量单位等
suffix.dic:特殊词库:后缀名
surname.dic:特殊词库:百家姓
preposition:特殊词库:语气词
自定义词库:比如当下流行词:857、emmm...、996
热更新:
修改ik分词器源码
基于ik分词器原生支持的热更新方案,部署web服务器,提供http接口,通过modified和tag两个http响应头,来提供词语的热更新
|
1
2
3
4
5
6
7
8
| GET _analyze
{
"text": "你的衣服真好看",
"analyzer": "ik_max_word"
}
输出结果:
你、的、衣服、真好、好看
|
1
2
3
4
5
6
7
8
| GET _analyze
{
"text": "你的衣服真好看",
"analyzer": "ik_smart"
}
输出结果:
你、的、衣服、真、好看
|