[root@k8s-master01 ~]# kubeadm init --kubernetes-version=v1.21.0 --pod-network-cidr=10.244.0.0/16 --apiserver-advertise-address=192.168.1.19 [init] Using Kubernetes version: v1.21.0 [preflight] Running pre-flight checks [preflight] Pulling images required for setting up a Kubernetes cluster [preflight] This might take a minute or two, depending on the speed of your internet connection [preflight] You can also perform this action in beforehand using 'kubeadm config images pull' [certs] Using certificateDir folder "/etc/kubernetes/pki" [certs] Generating "ca" certificate and key [certs] Generating "apiserver" certificate and key [certs] apiserver serving cert is signed for DNS names [k8s-master01 kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 192.168.1.19] [certs] Generating "apiserver-kubelet-client" certificate and key [certs] Generating "front-proxy-ca" certificate and key [certs] Generating "front-proxy-client" certificate and key [certs] Generating "etcd/ca" certificate and key [certs] Generating "etcd/server" certificate and key [certs] etcd/server serving cert is signed for DNS names [k8s-master01 localhost] and IPs [192.168.1.19 127.0.0.1 ::1] [certs] Generating "etcd/peer" certificate and key [certs] etcd/peer serving cert is signed for DNS names [k8s-master01 localhost] and IPs [192.168.1.19 127.0.0.1 ::1] [certs] Generating "etcd/healthcheck-client" certificate and key [certs] Generating "apiserver-etcd-client" certificate and key [certs] Generating "sa" key and public key [kubeconfig] Using kubeconfig folder "/etc/kubernetes" [kubeconfig] Writing "admin.conf" kubeconfig file [kubeconfig] Writing "kubelet.conf" kubeconfig file [kubeconfig] Writing "controller-manager.conf" kubeconfig file [kubeconfig] Writing "scheduler.conf" kubeconfig file [kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env" [kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml" [kubelet-start] Starting the kubelet [control-plane] Using manifest folder "/etc/kubernetes/manifests" [control-plane] Creating static Pod manifest for"kube-apiserver" [control-plane] Creating static Pod manifest for"kube-controller-manager" [control-plane] Creating static Pod manifest for"kube-scheduler" [etcd] Creating static Pod manifest forlocal etcd in"/etc/kubernetes/manifests" [wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s [kubelet-check] Initial timeout of 40s passed. [apiclient] All control plane components are healthy after 62.001527 seconds [upload-config] Storing the configuration used in ConfigMap "kubeadm-config"in the "kube-system" Namespace [kubelet] Creating a ConfigMap "kubelet-config-1.21"in namespace kube-system with the configuration for the kubelets in the cluster [upload-certs] Skipping phase. Please see --upload-certs [mark-control-plane] Marking the node k8s-master01 as control-plane by adding the labels: [node-role.kubernetes.io/master(deprecated) node-role.kubernetes.io/control-plane node.kubernetes.io/exclude-from-external-load-balancers] [mark-control-plane] Marking the node k8s-master01 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule] [bootstrap-token] Using token: 37exic.msprw2ejmhr9sgnm [bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles [bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to get nodes [bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials [bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token [bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster [bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace [kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key [addons] Applied essential addon: CoreDNS [addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
Alternatively, if you are the root user, you can run:
export KUBECONFIG=/etc/kubernetes/admin.conf
You should now deploy a pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
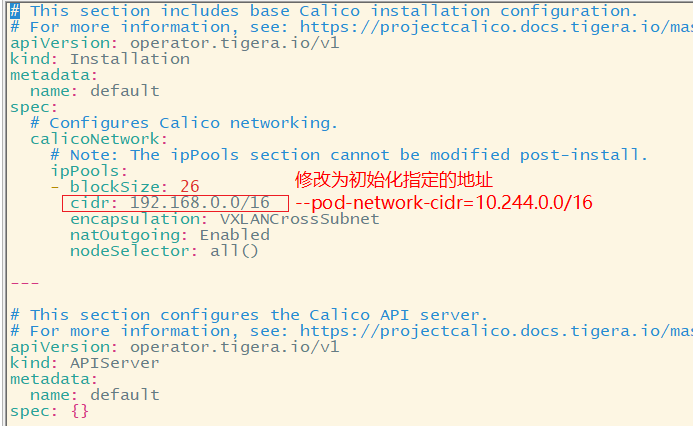
#因为需要修改default IP pool CIDR to match your pod network CIDR,所以不建议直接执行 #kubectl create -f https://raw.githubusercontent.com/projectcalico/calico/v3.24.1/manifests/custom-resources.yaml
#查看命名空间 [root@k8s-master01 calicofir]# kubectl get ns NAME STATUS AGE calico-system Active 79s default Active 10h kube-node-lease Active 10h kube-public Active 10h kube-system Active 10h tigera-operator Active 9m3s
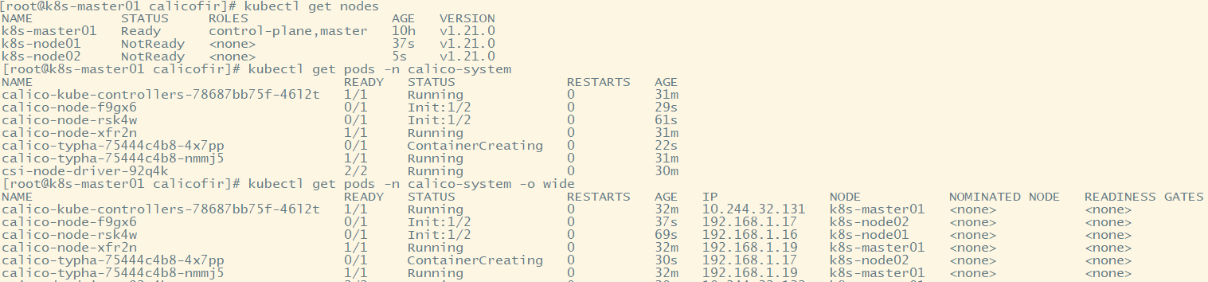
#查看calico-system命名空间下的pod [root@k8s-master01 calicofir]# kubectl get pods -n calico-system NAME READY STATUS RESTARTS AGE calico-kube-controllers-78687bb75f-46l2t 0/1 Pending 0 94s calico-node-xfr2n 0/1 PodInitializing 0 94s calico-typha-75444c4b8-nmmj5 1/1 Running 0 94s csi-node-driver-92q4k 0/2 ContainerCreating 0 4s
#监控calico-system相关pod安装情况 watch kubectl get pods -n calico-system Every 2.0s: kubectl get pods -n calico-system Sun Sep 11 09:39:03 2022
NAME READY STATUS RESTARTS AGE calico-kube-controllers-78687bb75f-46l2t 1/1 Running 0 8m26s calico-node-xfr2n 1/1 Running 0 8m26s calico-typha-75444c4b8-nmmj5 1/1 Running 0 8m26s csi-node-driver-92q4k 2/2 Running 0 6m56s
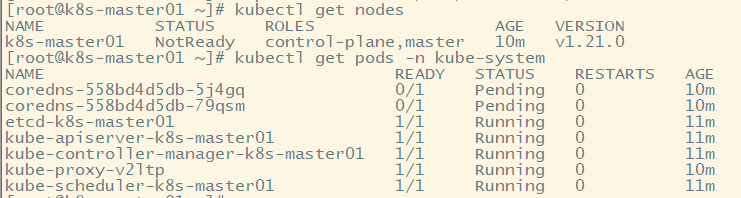
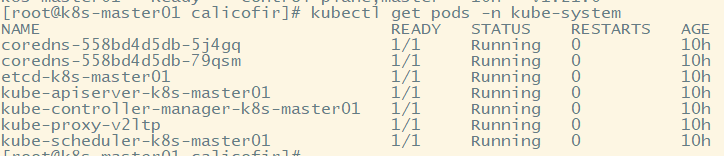
此时再看coredns处于Running状态表明联网成功。
calico客户端安装
1 2 3 4 5 6 7
#下载二进制文件 安装 cd /usr/local/calicofir curl -L https://github.com/projectcalico/calico/releases/download/v3.21.4/calicoctl-linux-amd64 -o calicoctl #添加权限 chmod +x /usr/local/calicofir/calicoctl calicoctl version
工作节点加入集群
1 2 3 4 5
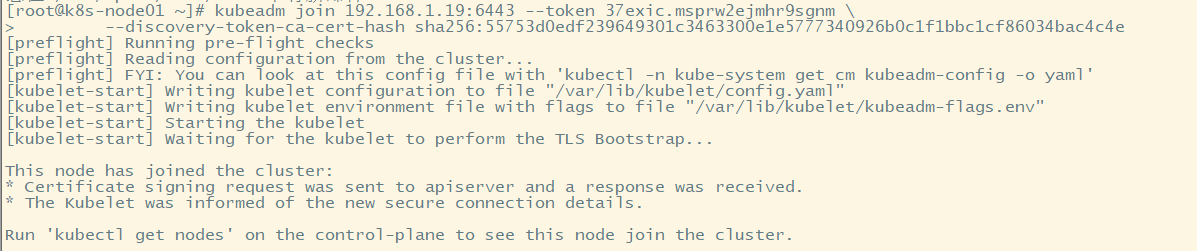
#在之前初始化后控制台打印输出以下语句,将其粘贴到需要加入集群的主机上执行 Then you can join any number of worker nodes by running the following on each as root: