[root@k8s-master1 ~]# kubectl apply -f pod1.yml pod/pod-stress created
3.2.2 查看pod信息
查看pod信息
1 2 3
[root@k8s-master1 ~]# kubectl get pod NAME READY STATUS RESTARTS AGE pod-stress 1/1 Running 0 45s
查看pod详细信息
1 2 3
[root@k8s-master1 ~]# kubectl get pods -o wide NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES pod-stress 1/1 Running 0 71s 10.244.194.72 k8s-worker1 <none> <none>
描述pod详细信息
1 2 3 4 5 6 7 8 9 10
[root@k8s-master1 ~]# kubectl describe pod pod-stress ...... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 102s default-scheduler Successfully assigned default/pod-stress to k8s-worker1 Normal Pulling 102s kubelet Pulling image "polinux/stress" Normal Pulled 83s kubelet Successfully pulled image "polinux/stress"in 18.944533343s Normal Created 83s kubelet Created container c1 Normal Started 82s kubelet Started container c1
3.3 删除pod
3.3.1 单个pod删除
1 2 3 4 5
#方法1 [root@k8s-master1 ~]# kubectl delete pod pod-stress pod "pod-stress" deleted #方法2 [root@k8s-master1 ~]# kubectl delete -f pod1.yml
[root@k8s-master1 ~]# kubectl describe pod pod-stress ...... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 102s default-scheduler Successfully assigned default/pod-stress to k8s-worker1 Normal Pulling 102s kubelet Pulling image "polinux/stress" Normal Pulled 83s kubelet Successfully pulled image "polinux/stress"in 18.944533343s Normal Created 83s kubelet Created container c1 Normal Started 82s kubelet Started container c1
[root@k8s-master1 ~]# kubectl describe pod pod-stress ...... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 17s default-scheduler Successfully assigned default/pod-stress to k8s-worker1 Normal Pulled 17s kubelet Container image "polinux/stress" already present on machine Normal Created 17s kubelet Created container c1 Normal Started 17s kubelet Started container c1
说明: 第二行信息是说镜像已经存在,直接使用了
3.5 pod的标签
为pod设置label,用于控制器通过label与pod关联
语法与前面学的node标签几乎一致
3.5.1 通过命令管理Pod标签
查看pod的标签
1 2 3
[root@k8s-master1 ~]# kubectl get pods --show-labels NAME READY STATUS RESTARTS AGE LABELS pod-stress 1/1 Running 0 7m25s <none>
[root@k8s-master1 ~]# kubectl get pods --show-labels NAME READY STATUS RESTARTS AGE LABELS pod-stress 1/1 Running 0 8m54s bussiness=game,env=test,region=huanai,zone=A
通过等值关系标签查询
1 2 3
[root@k8s-master1 ~]# kubectl get pods -l zone=A NAME READY STATUS RESTARTS AGE pod-stress 1/1 Running 0 9m22s
通过集合关系标签查询
1 2 3
[root@k8s-master1 ~]# kubectl get pods -l "zone in (A,B,C)" NAME READY STATUS RESTARTS AGE pod-stress 1/1 Running 0 9m55s
[root@k8s-master1 ~]# kubectl exec pod-stress4 -- touch /222 Defaulting container name to c1. Use 'kubectl describe pod/pod-stress4 -n default' to see all of the containers in this pod.
3.8.3 和容器交互操作
和docker exec几乎一样
1 2 3 4 5 6 7
[root@k8s-master1 ~]# kubectl exec -it pod-stress4 -c c1 -- /bin/bash bash-5.0# touch /333 bash-5.0# ls 222 bin etc lib mnt proc run srv tmp var 333 dev home media opt root sbin sys usr bash-5.0# exit exit
3.9 验证pod中多个容器网络共享
编写YAML
1 2 3 4 5 6 7 8 9 10 11 12
[root@k8s-master1 ~]# vim pod-nginx.yaml apiVersion: v1 kind: Pod metadata: name: nginx2 spec: containers: - name: c1 image: nginx:1.15-alpine
- name: c2 image: nginx:1.15-alpine
应用YAML
1 2
[root@k8s-master1 ~]# kubectl apply -f pod-nginx.yaml pod/nginx2 created
查看pod信息与状态
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18
[root@k8s-master1 ~]# kubectl describe pod nginx2 ...... ...... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 25s default-scheduler Successfully assigned default/nginx2 to k8s-worker1 Normal Pulling 24s kubelet Pulling image "nginx:1.15-alpine" Normal Pulled 5s kubelet Successfully pulled image "nginx:1.15-alpine"in 18.928009025s Normal Created 5s kubelet Created container c1 Normal Started 5s kubelet Started container c1 Normal Pulled 2s (x2 over 5s) kubelet Container image "nginx:1.15-alpine" already present on machine Normal Created 2s (x2 over 5s) kubelet Created container c2 Normal Started 2s (x2 over 5s) kubelet Started container c2 [root@k8s-master1 ~]# kubectl get pods |grep nginx2 nginx2 1/2 CrashLoopBackOff 3 2m40s #有一个启不来,因为一个容器中两个pod是共用网络的,所以不能两个都占用80端口
[root@k8s-worker1 ~]# docker logs k8s_c2_nginx2_default_51fd8e81-1c4b-4557-9498-9b25ed8a4c99_4 2020/11/21 04:29:12 [emerg] 1#1: bind() to 0.0.0.0:80 failed (98: Address in use) nginx: [emerg] bind() to 0.0.0.0:80 failed (98: Address in use) 2020/11/21 04:29:12 [emerg] 1#1: bind() to 0.0.0.0:80 failed (98: Address in use) nginx: [emerg] bind() to 0.0.0.0:80 failed (98: Address in use) 2020/11/21 04:29:12 [emerg] 1#1: bind() to 0.0.0.0:80 failed (98: Address in use) nginx: [emerg] bind() to 0.0.0.0:80 failed (98: Address in use) 2020/11/21 04:29:12 [emerg] 1#1: bind() to 0.0.0.0:80 failed (98: Address in use) nginx: [emerg] bind() to 0.0.0.0:80 failed (98: Address in use) 2020/11/21 04:29:12 [emerg] 1#1: bind() to 0.0.0.0:80 failed (98: Address in use) nginx: [emerg] bind() to 0.0.0.0:80 failed (98: Address in use) 2020/11/21 04:29:12 [emerg] 1#1: still could not bind() nginx: [emerg] still could not bind()
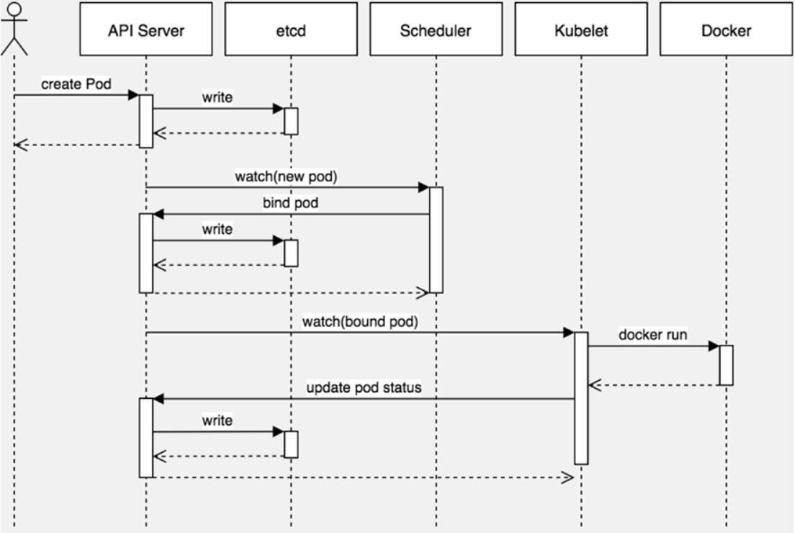
四、pod调度
4.1 pod调度流程
Step1 通过kubectl命令应用资源清单文件(yaml格式)向api server 发起一个create pod 请求
[root@k8s-master1 ~]# kubectl apply -f pod-nodename.yml pod/pod-nodename created
验证
1 2 3 4 5 6 7 8 9
[root@k8s-master1 ~]# kubectl describe pod pod-nodename |tail -6 Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Pulled 2m47s kubelet Container image "nginx:1.15-alpine" already present on machine Normal Created 2m47s kubelet Created container nginx Normal Started 2m47s kubelet Started container nginx
[root@k8s-master1 ~]# vim pod-nodeselector.yml apiVersion: v1 kind: Pod metadata: name: pod-nodeselect spec: nodeSelector: # nodeSelector节点选择器 bussiness: game # 指定调度到标签为bussiness=game的节点 containers: - name: nginx image: nginx:1.15-alpine
应用YAML文件创建pod
1 2
[root@k8s-master1 ~]# kubectl apply -f pod-nodeselector.yml pod/pod-nodeselect created
验证
1 2 3 4 5 6 7 8 9
[root@k8s-master1 ~]# kubectl describe pod pod-nodeselect |tail -6 Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 20s default-scheduler Successfully assigned default/pod-nodeselect to k8s-worker1 Normal Pulled 19s kubelet Container image "nginx:1.15-alpine" already present on machine Normal Created 19s kubelet Created container nginx Normal Started 19s kubelet Started container nginx
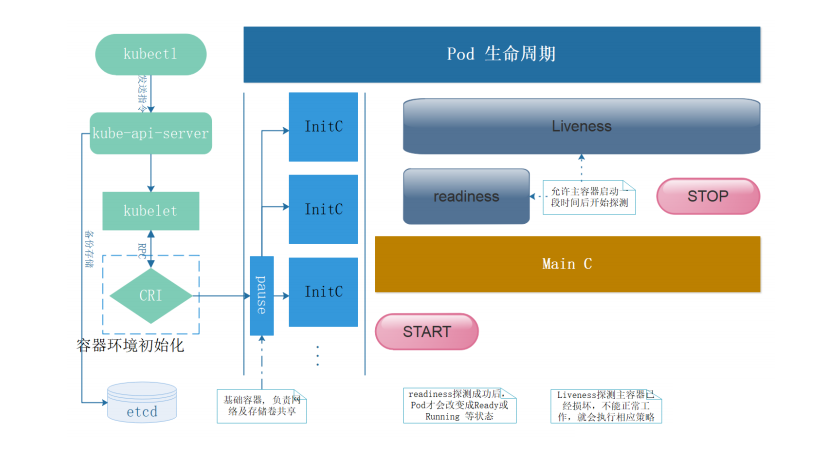
指示容器是否准备好为请求提供服务。如果就绪态探测失败, 端点控制器将从与 Pod 匹配的所有服务的端点列表中删除该 Pod 的 IP 地址。 初始延迟之前的就绪态的状态值默认为 Failure。 如果容器不提供就绪态探针,则默认状态为 Success。注:检查后不健康,将容器设置为Notready;如果使用service来访问,流量不会转发给此种状态的pod
[root@k8s-master1 ~]# kubectl describe pod liveness-exec ...... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 40s default-scheduler Successfully assigned default/liveness-exec to k8s-worker1 Normal Pulled 38s kubelet Container image "busybox" already present on machine Normal Created 37s kubelet Created container liveness Normal Started 37s kubelet Started container liveness Warning Unhealthy 3s kubelet Liveness probe failed: cat: can't open '/tmp/healthy': No such file or directory #看到40s前被调度以k8s-worker1节点,3s前健康检查出问题
过几分钟再观察
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
[root@k8s-master1 ~]# kubectl describe pod liveness-exec ...... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 3m42s default-scheduler Successfully assigned default/liveness-exec to k8s-worker1 Normal Pulled 70s (x3 over 3m40s) kubelet Container image "busybox" already present on machine Normal Created 70s (x3 over 3m39s) kubelet Created container liveness Normal Started 69s (x3 over 3m39s) kubelet Started container liveness Warning Unhealthy 26s (x9 over 3m5s) kubelet Liveness probe failed: cat: can't open '/tmp/healthy': No such file or directory Normal Killing 26s (x3 over 2m55s) kubelet Container liveness failed liveness probe, will be restarted [root@k8s-master1 ~]# kubectl get pod NAME READY STATUS RESTARTS AGE liveness-exec 1/1 Running 3 4m12s #看到重启3次,慢慢地重启间隔时间会越来越长