安装
Windows安装
如果尚未安装,则使用OpenJDK 8或Oracle Java 8,推荐用于Neo4j 3.0.x Version 7推荐用于2.3.0之前的版本。
找到您刚刚下载的zip文件并右键单击,解压缩所有文件。
将解压缩的文件放在服务器上的永久主目录中,例如
D:\neo4j\。顶级目录称为NEO4J_HOME。要将Neo4j作为控制台应用程序运行,请使用:
<NEO4J_HOME>\bin\neo4j console要将Neo4j作为服务使用安装:
<NEO4J_HOME>\bin\neo4j install-service.有关其他命令和了解Zip文件中包含的Windows PowerShell模块,请参阅Windows安装文档。
Docker安装
拉取镜像
docker pull neo4j:3.5.22-community运行镜像
1
2
3
4
5
6
7docker run -d -p 7474:7474 -p 7687:7687 --name neo4j \
-e "NEO4J_AUTH=neo4j/123456" \
-v /usr/local/soft/neo4j/data:/data \
-v /usr/local/soft/neo4j/logs:/logs \
-v /usr/local/soft/neo4j/conf:/var/lib/neo4j/conf \
-v /usr/local/soft/neo4j/import:/var/lib/neo4j/import \
neo4j:3.5.22-community
Linux安装
tar -xf neo4j-community-3.5.35-unix.tar.gz- 将解压缩的文件放在服务器上的永久主目录中。顶级目录称为
NEO4J_HOME。- 要将Neo4j作为控制台应用程序运行,使用:
<NEO4J_HOME>/bin/neo4j console - 要在后台进程中运行Neo4j,使用:
<NEO4J_HOME>/bin/neo4j start - 有关其他命令,请参阅Unix tarball安装文档。
- 要将Neo4j作为控制台应用程序运行,使用:
浏览器访问
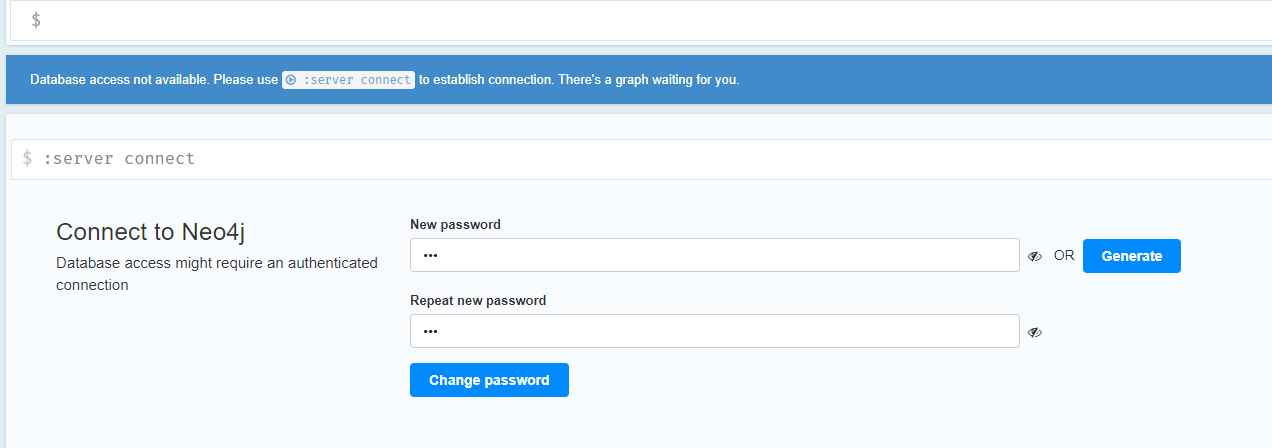
在浏览器中访问:http://localhost:7474。
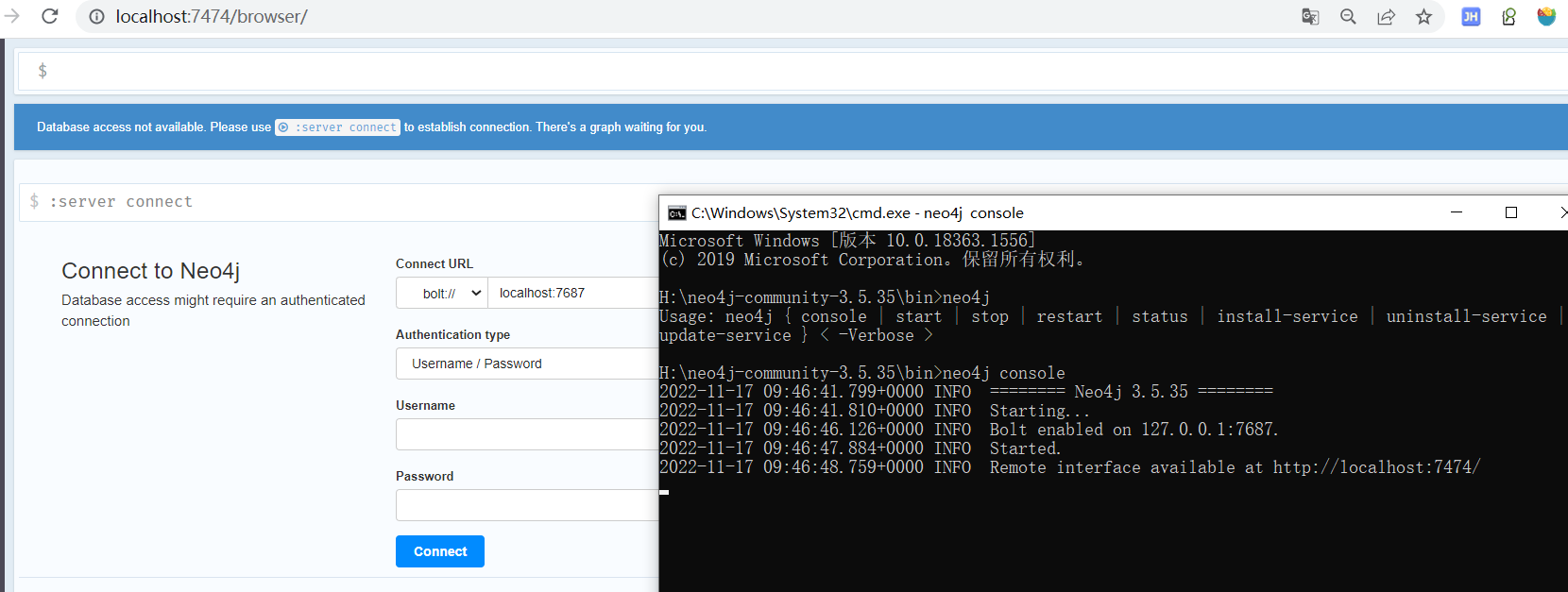
使用用户名’neo4j’和默认密码’neo4j’进行连接。然后系统会提示更改密码。
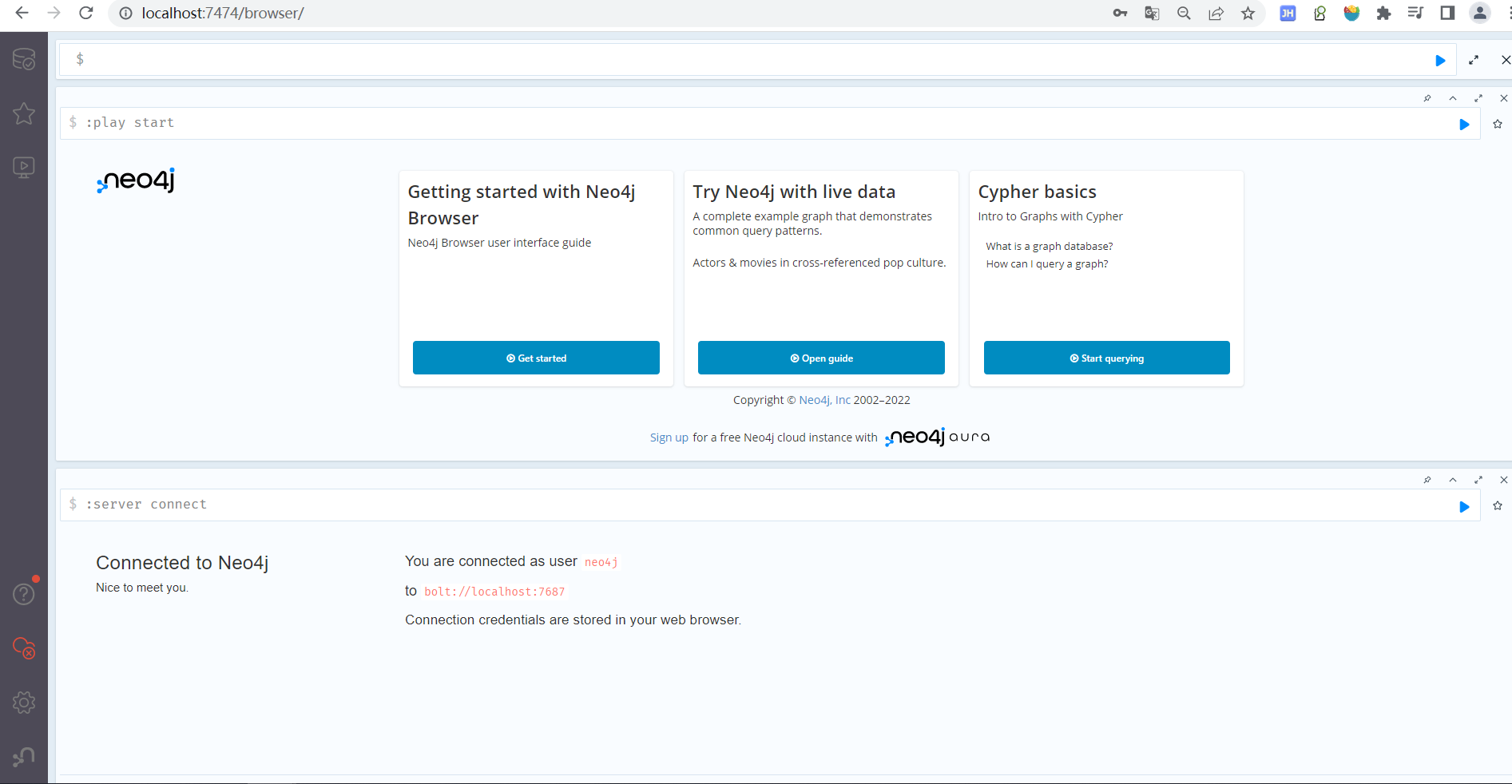
- Neo4j浏览器是开发人员探索Neo4j数据库、执行Cypher查询并以表格或图表形式查看结果的工具。你甚至可以使用浏览器来:
- 导入数据
- 在Java中调用用户定义过程
- 配置文件查询,使用EXPLAIN和Profile查看执行计划。
CQL语句
CQL简介
Neo4j的Cypher语言是为处理图形数据而构建的,CQL代表Cypher查询语言。像Oracle数据库具有查询 语言SQL,Neo4j具有CQL作为查询语言。
- 它是Neo4j图形数据库的查询语言。
- 它是一种声明性模式匹配语言
- 它遵循SQL语法。
- 它的语法是非常简单且人性化、可读的格式。
| CQL命令 | 用户 |
|---|---|
| CREATE | 创建节点、关系和属性 |
| MATCH | 检索有关节点、关系和属性 |
| RETURN | 返回查询结构 |
| WHERE | 提供条件过滤检索数据 |
| DELETE | 删除节点和关系 |
| REMOVE | 删除节点和关系的属性 |
| ORDER BY | 排序检索数据 |
| SET | 添加或更新标签 |
CREATE
创建节点
创建没有属性的节点
1
CREATE (<node-name>:<label-name>)
使用属性创建节点
1
CREATE (<node-name>:<label-name>{<propertyKey1>:<propertValue1>,<propertyKey2>:<propertValue2>})
创建关系
在没有属性的节点之间创建关系
1
CREATE (node1-name:lable1) - [relationship-name:relationship-lable] -> (node2-name:lable2)
创建node1、node2,同时创建node1指向node2的关系
使用属性创建节点之间的关系
创建标签
为节点或关系创建单个或多个标签
1
CREATE(node-name:lable-name1:lable-name2)
语法
1 | CREATE (<node-name>:<label-name>) |
<node-name>:创建的节点名称
<label-name>:创建的节点标签名称不能使用
<node-name>来访问节点详细信息,应该使用此标签名称来访问节点详细信息,应该使用<label-name>来访问节点详细信息。
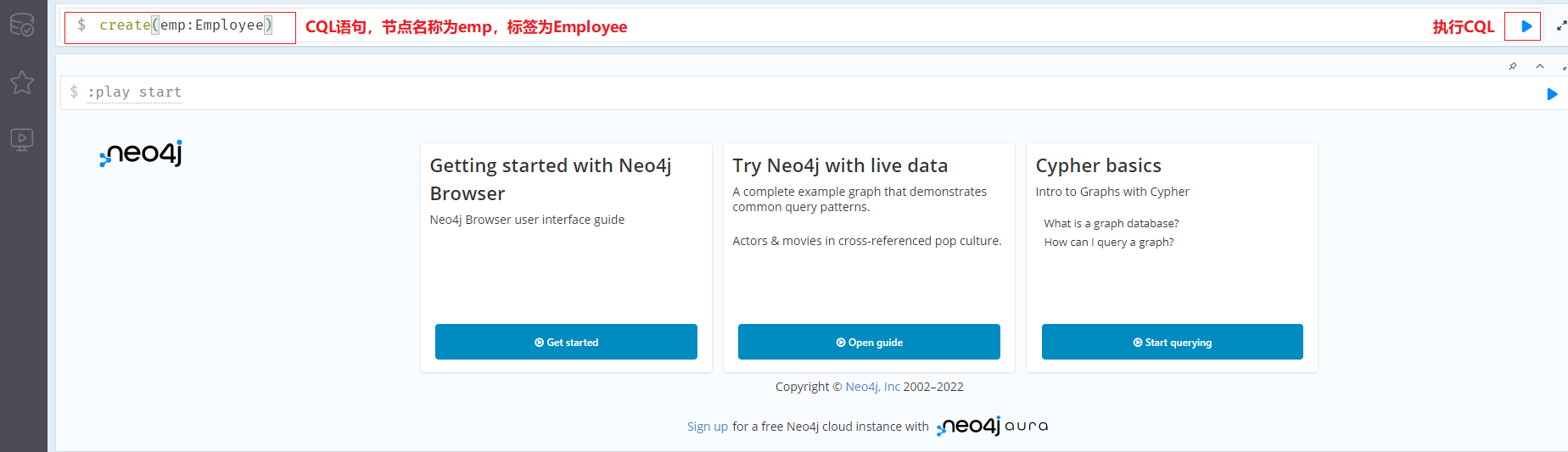
创建无属性节点
1 | create(emp:Employee) |
创建带属性节点
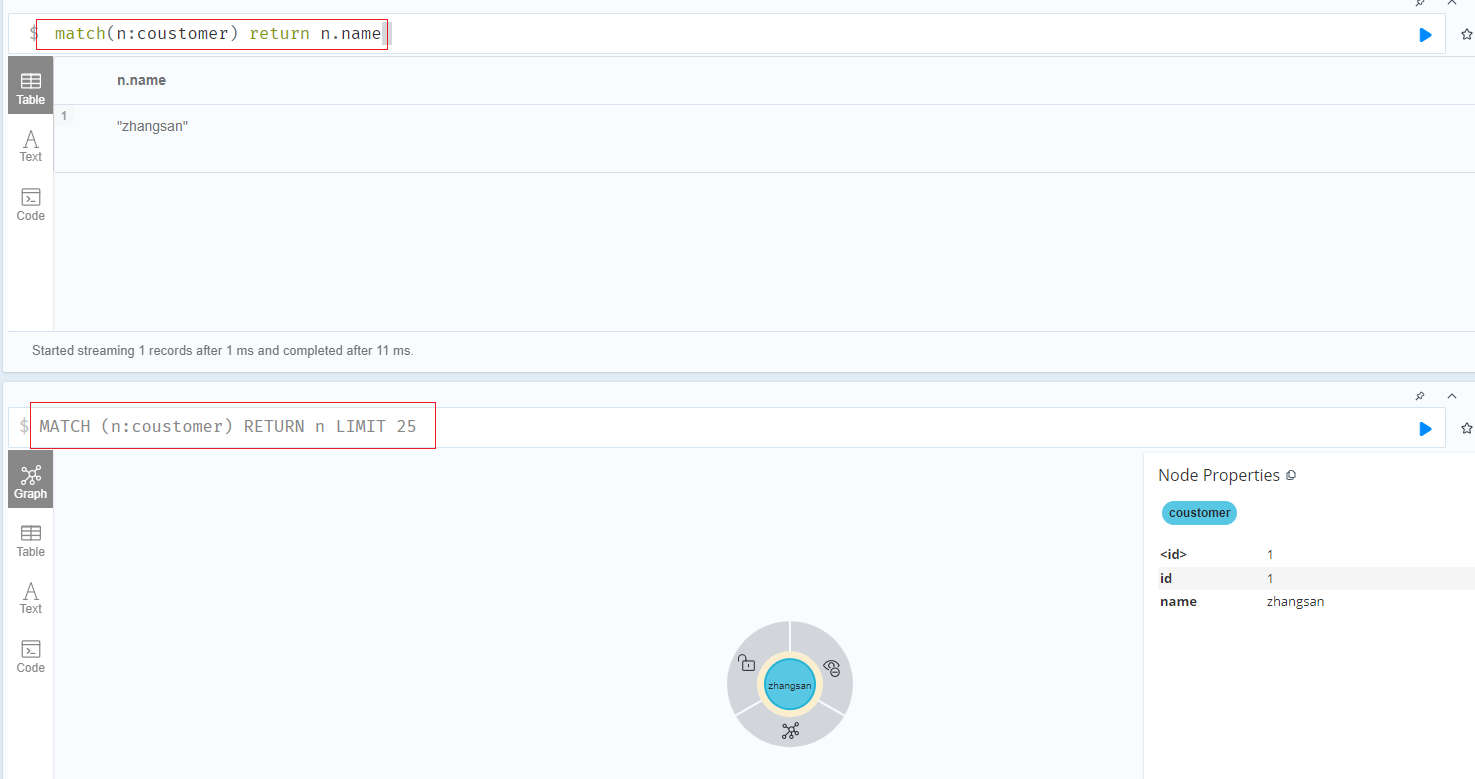
1 | create(c:coustomer{id:"1",name:"zhangsan"}) |
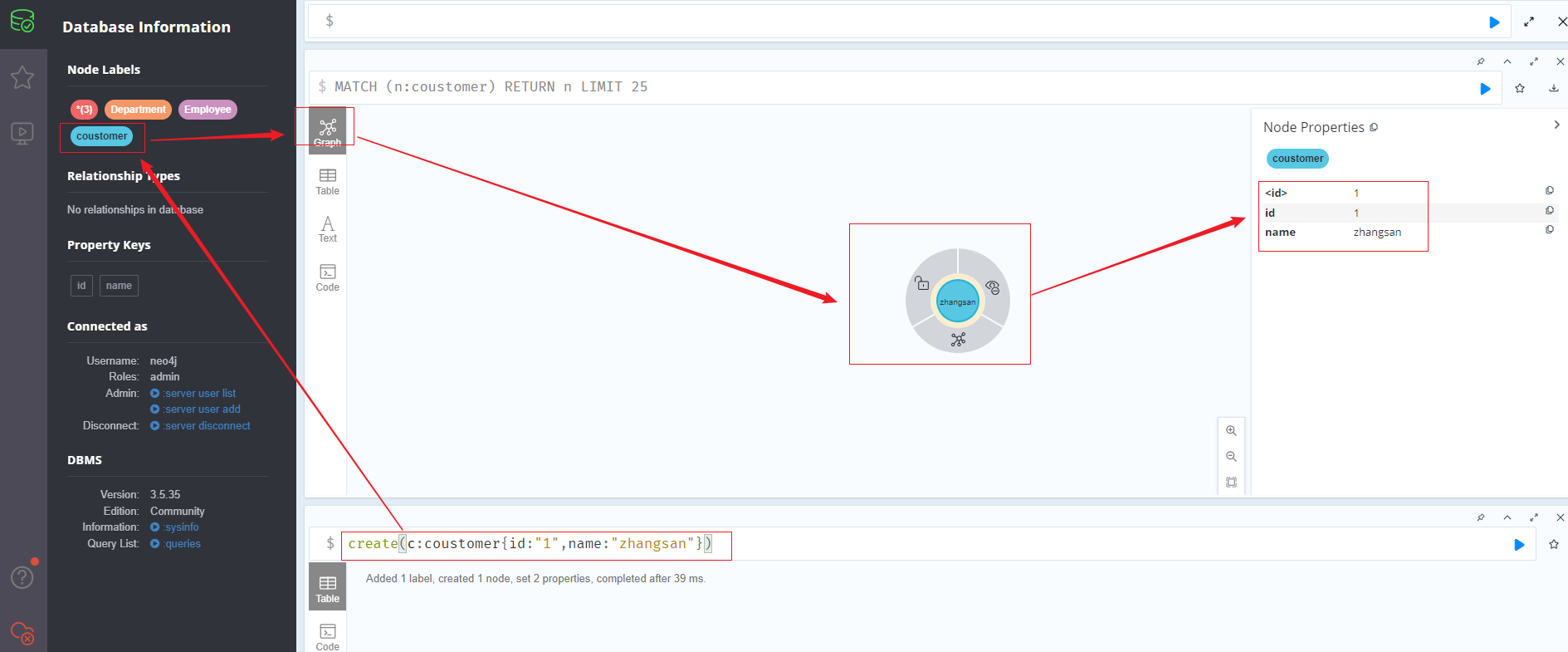
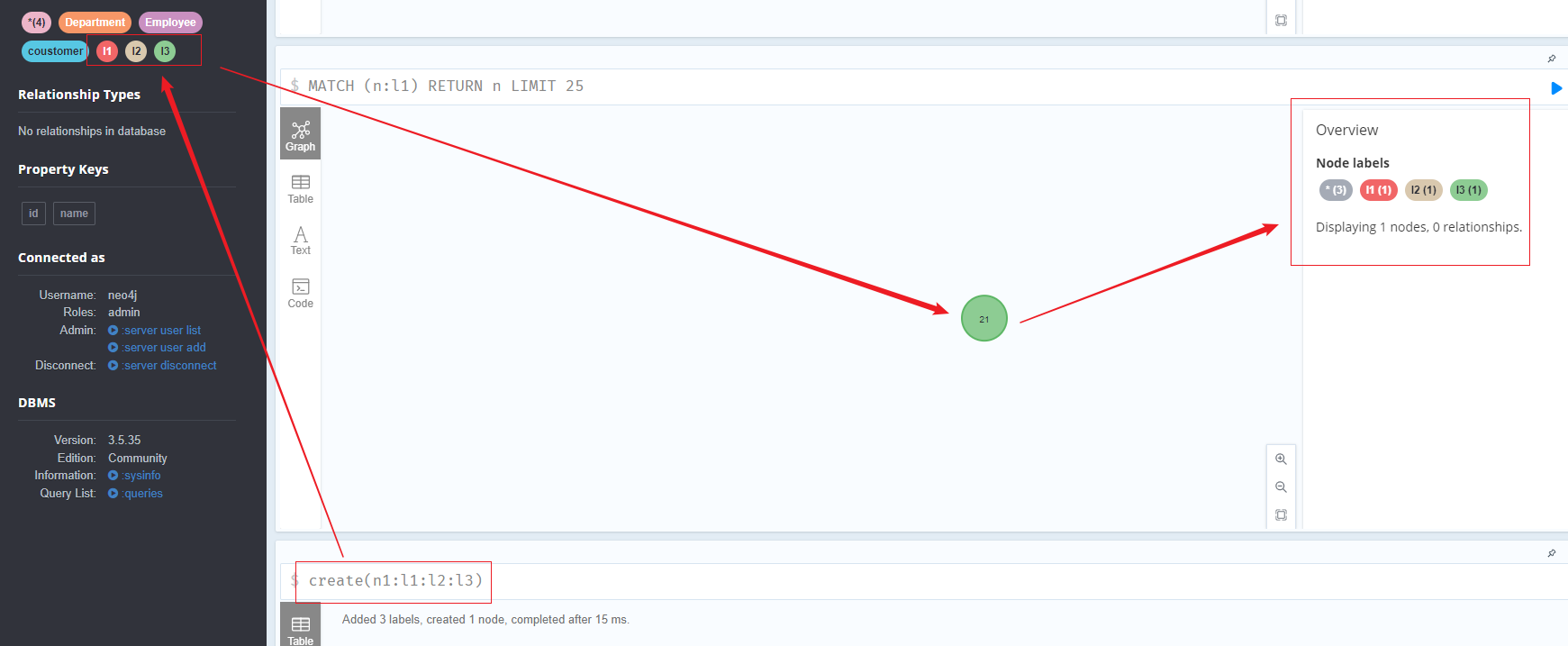
创建多标签节点
1 | create(n1:l1:l2:l3) |
n1 节点名称
l1、l2、l3都是标签
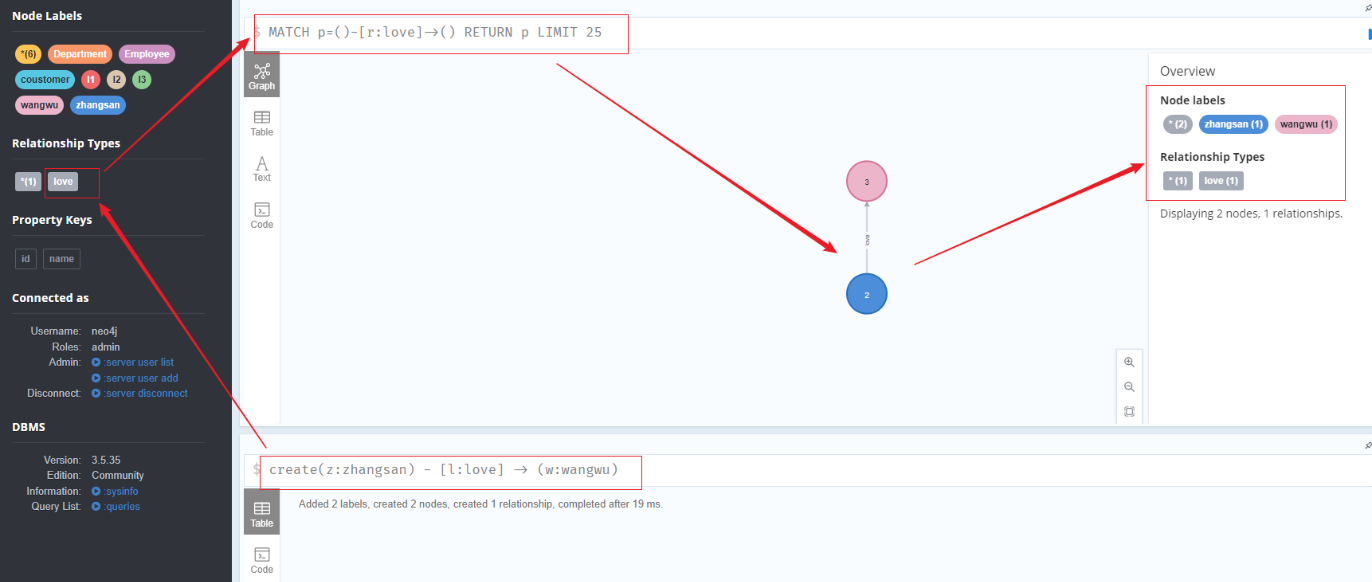
创建有关系节点
1 | create(z:zhangsan) - [l:love] -> (w:wangwu) |
MATCH
- 从数据库获取有关节点和属性的数据
- 从数据库获取有关节点,关系和属性的数据
语法
1 | MATCH (<node-name>:<label-name>) |
MATCH无法单独使用需要配合RETURN命令一起使用
RETURN
- 检索节点的某些属性
- 检索节点的所有属性
- 检索节点和关联关系的某些属性
- 检索节点和关联关系的所有属性
1 | RETURN |
<node-name>节点名称
<propertyn-name>属性是键值对形式,这里的<propertyn-name>指的是属性的key
MATCH和RETURN
CQL语句中MATCH 需要搭配RETURN命令 一起使用
- 检索节点的某些属性
- 检索节点的所有属性
- 检索节点和关联关系的某些属性
- 检索节点和关联关系的所有属性
语法
1 | MATCH Command |
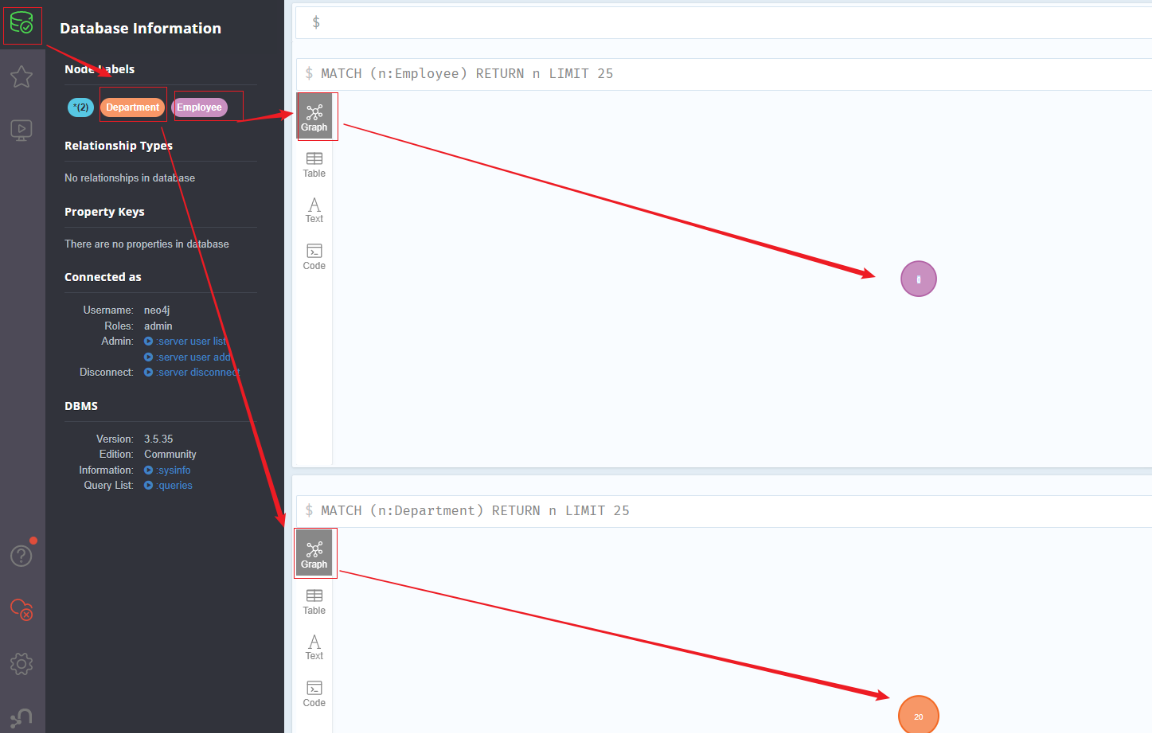
获取所有节点
1 | MATCH (n1) RETURN n1 LIMIT 25 |

获取含关系节点
1 | MATCH (n1)-[r]->(n2) RETURN r, n1, n2 LIMIT 25 |
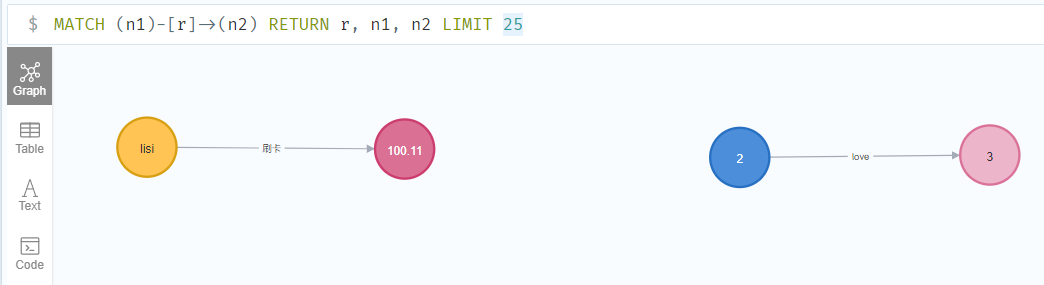
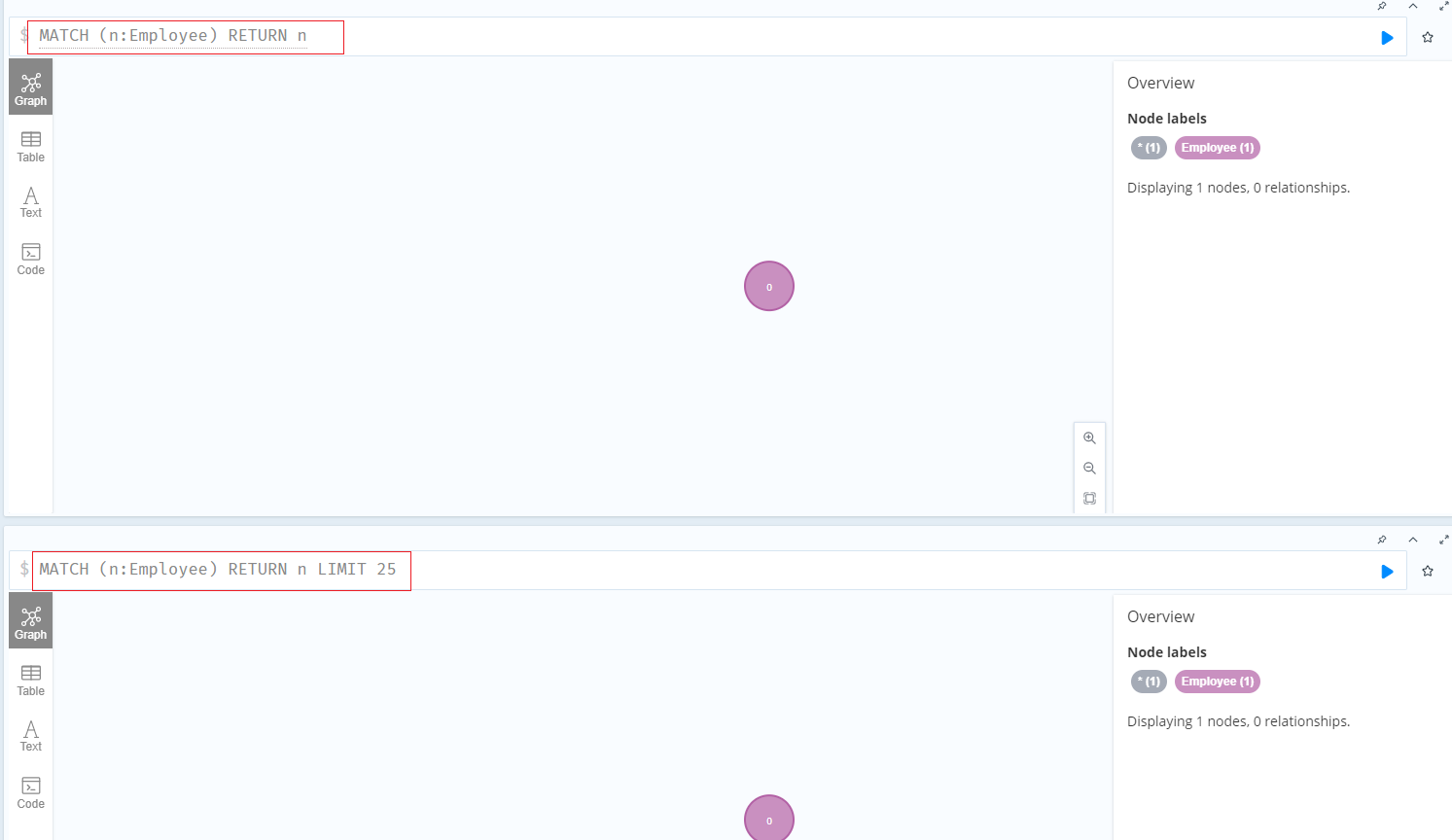
基于标签检索节点
1 | MATCH (n:Employee) RETURN n LIMIT 25 |
1 | match(n:coustomer) return n.name |
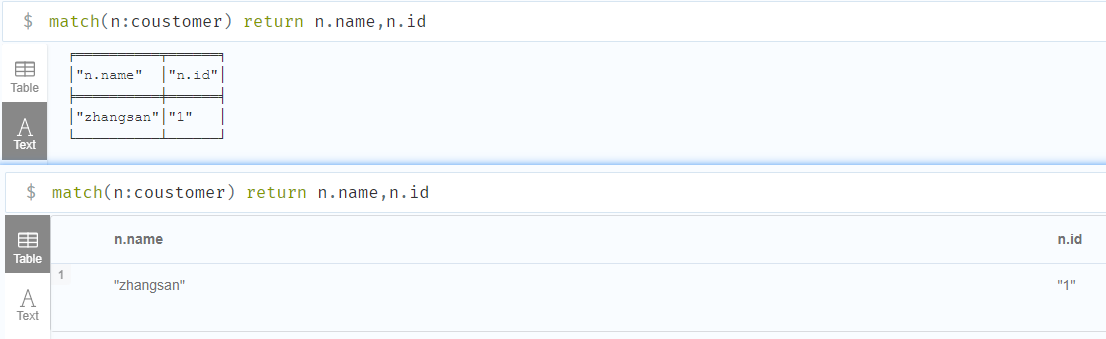
基于关系检索节点
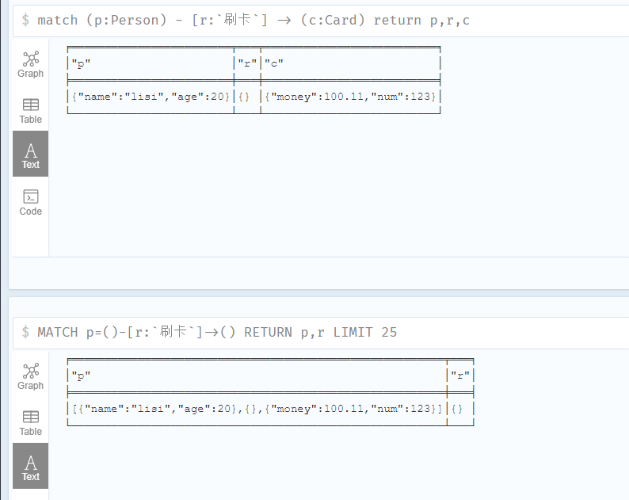
1 | match (p:Person) - [r:`刷卡`] -> (c:Card) return p,r,c |
MATCH和WHERE
像SQL一样,Neo4j CQL在CQL MATCH命令中提供了WHERE子句来过滤MATCH查询的结果。
语法结构
1 | WHERE <condition> |
操作符:AND、OR、NOT、XOR、=、<>、<、>、<=、>= 、in
单标签查询
创建三个标签为person的节点
1 | create(a:Person{name:"zhangsan",age:18}),(b:Person{name:"lisi",age:20}),(c:Person{name:"wangwu",age:25}) |
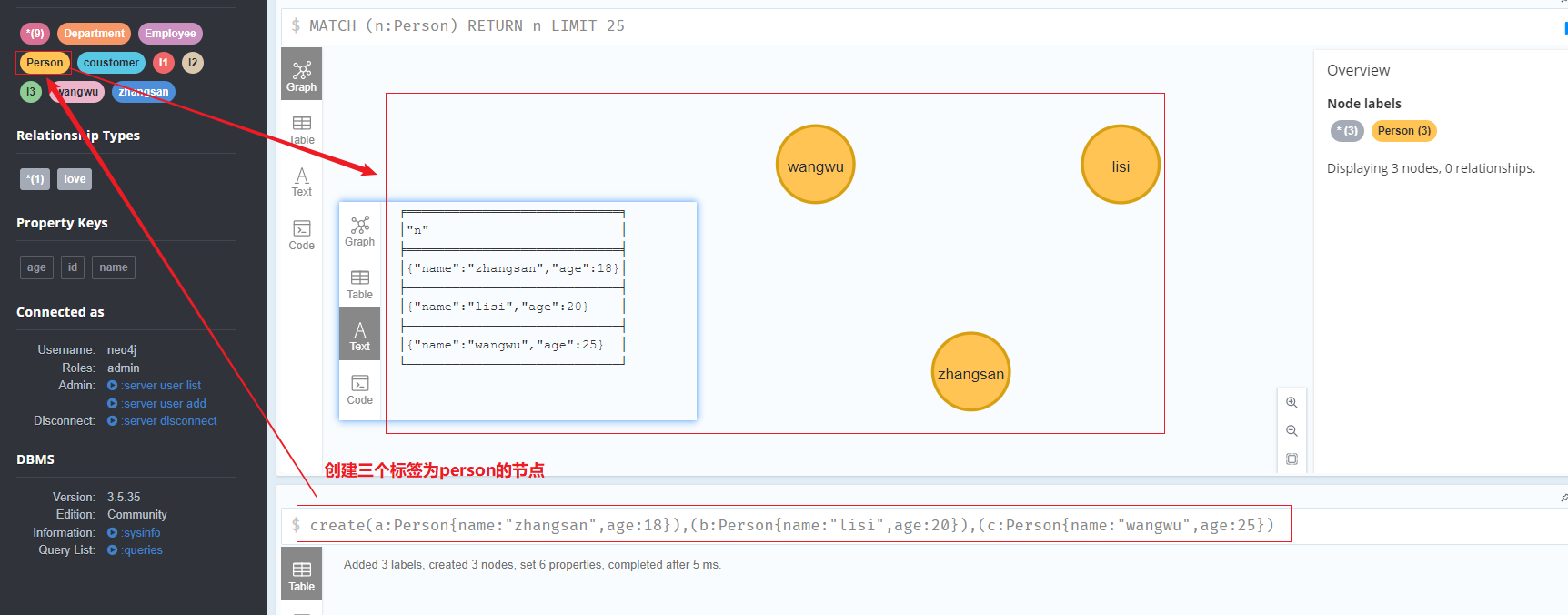
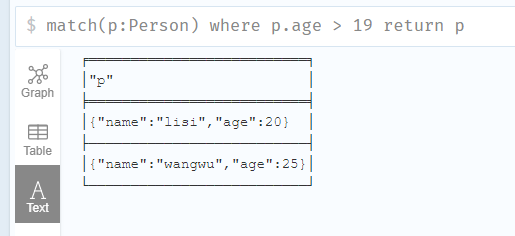
年龄大于19的节点
1 | match(p:Person) where p.age > 19 return p |
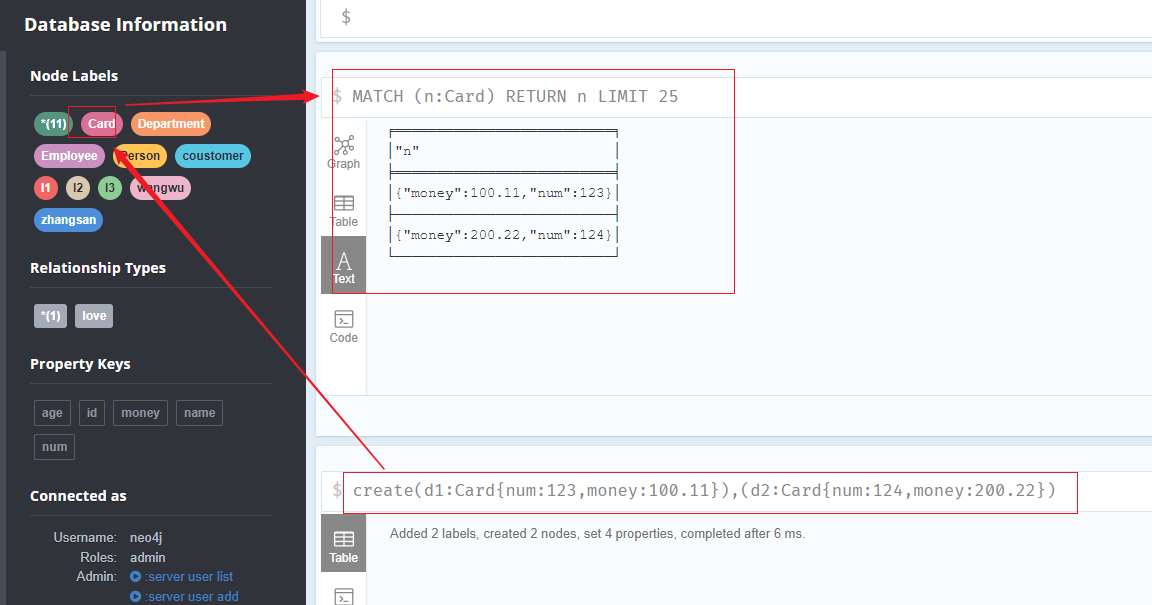
多标签查询
创建三个标签为card的节点
1 | create(d1:Card{num:123,money:100.11}),(d2:Card{num:124,money:200.22}) |
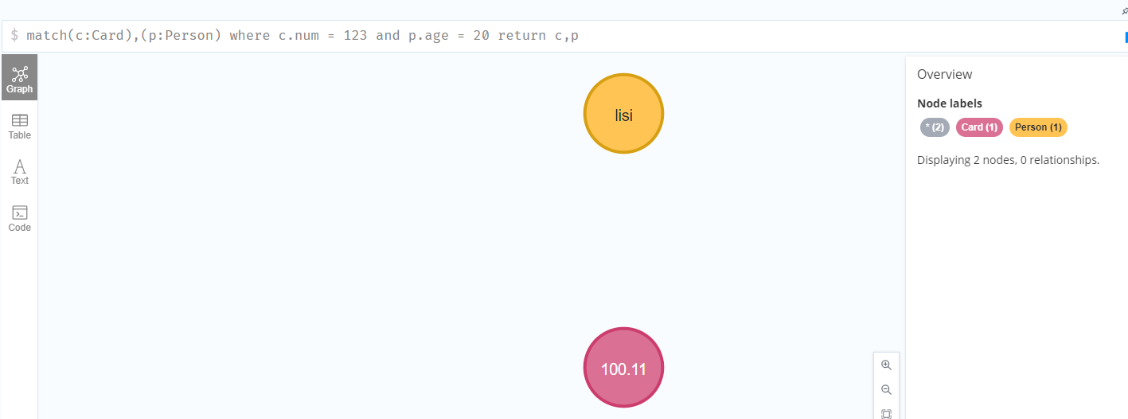
多个节点关联查询
1 | match(c:Card),(p:Person) where c.num = 123 and p.age = 20 return c,p |
注意大小写、值类型

创建关系
语法
1 | MATCH (<node1-label-name>:<node1-name>),(<node2-label-name>:<node2-name>) |
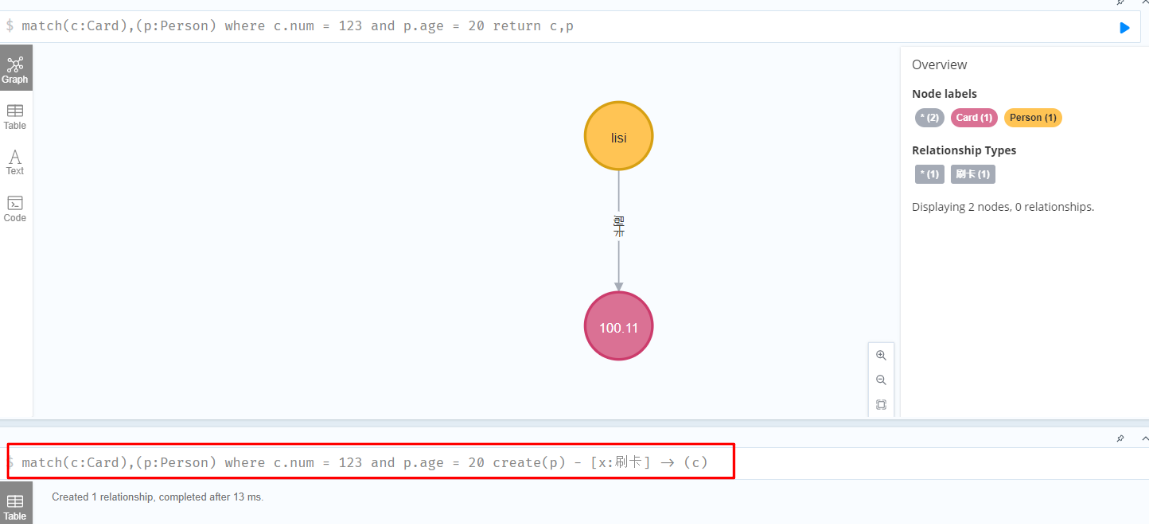
通过where查出两个节点并为他们创建关系
1 | match(c:Card),(p:Person) where c.num = 123 and p.age = 20 create(p) - [x:刷卡] -> (c) |
- 建立关系前
- 建立关系
MATCH和DELETE
删除节点。
存在关系的节点无法直接删除,需要先删除关系
删除节点及相关节点和关系。
语法
1 | DELETE <node-name-list> |
使用逗号(,)运算符来分隔节点名
根据标签删除节点
1 | match(n:Department) delete n |
该标签下所有节点都会被删除
含有关系的节点无法直接删除
删除关系
1 | match p=()-[r:love]->() delete r |
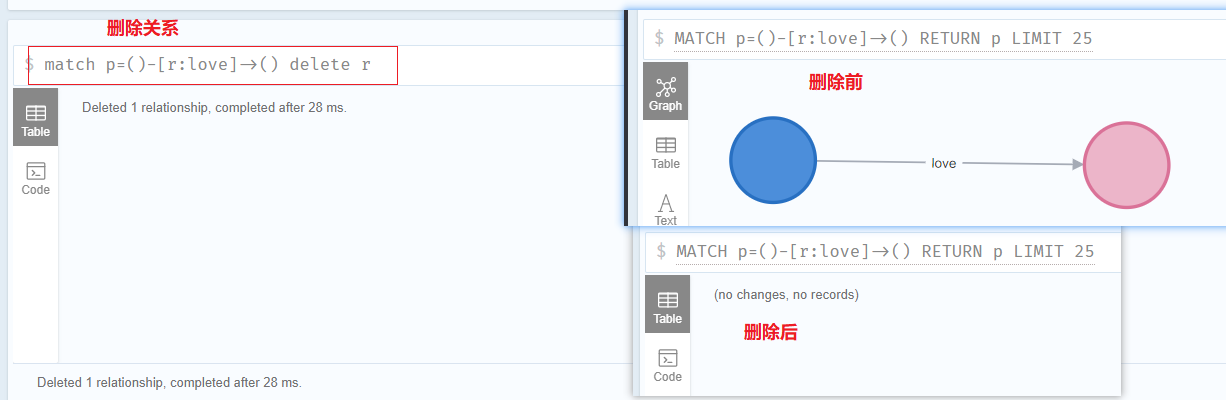
根据删除节点和关系
1 | //重新为两节点建立关系 |
限定标签条件删除
1 | match (n:Person) where n.age = 18 delete n |
删除符合条件的标签节点
MATCH和REMOVE
- 删除节点或关系的标签
- 删除节点或关系的属性
移除属性
1 | //创建节点 |
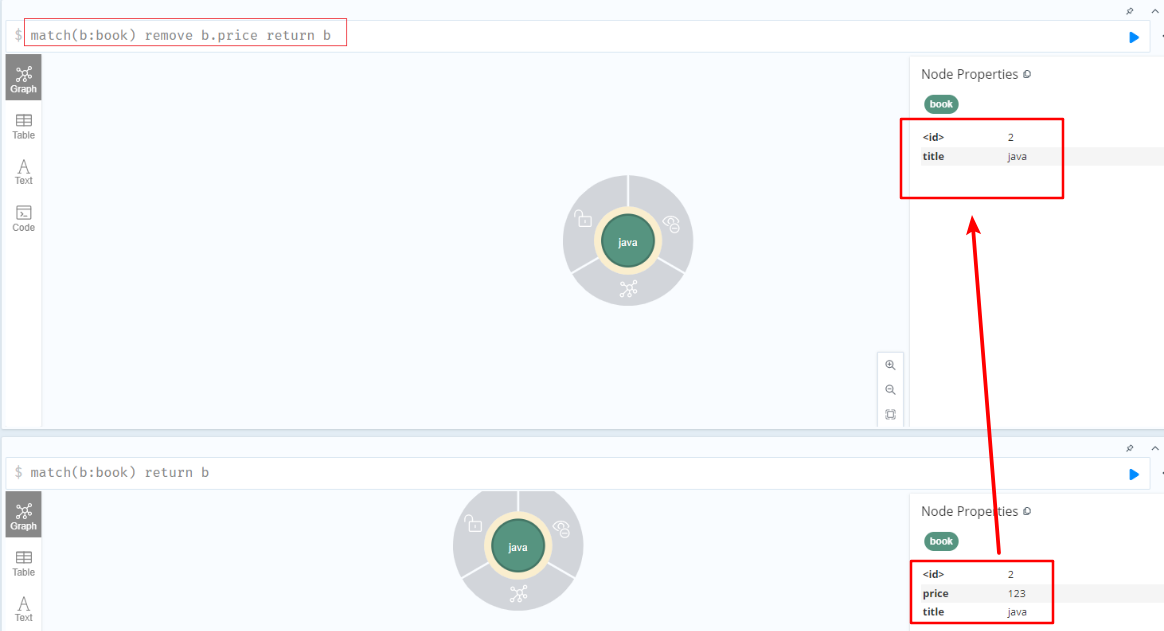
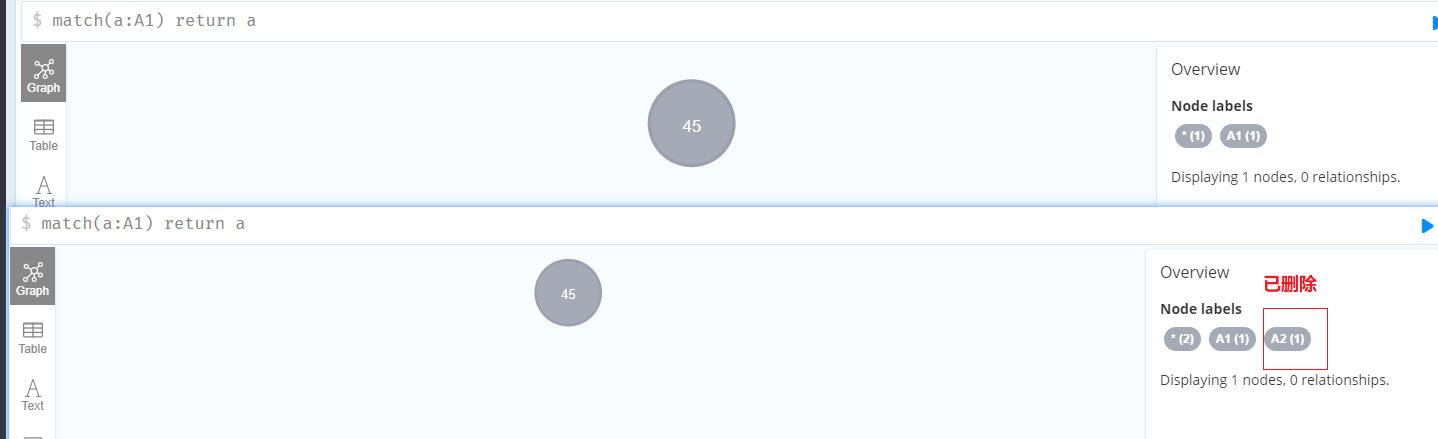
移除标签
1 | match(a:A1) remove a:A2 |
注意标签操作使用冒号
MATCH和SET
- 向现有节点或关系添加新属性
- 添加或更新属性值
设置标签
1 | match(a:A1) set a:A3 |
标签操作使用冒号
设置属性
1 | match (a:A1) SET a.title = '属性值' |
标签操作使用.
不存在则新增,存在则修改
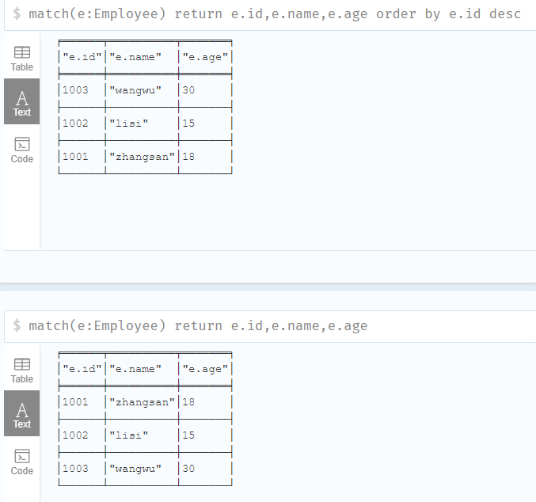
ORDER BY
Neo4j CQL在MATCH命令中提供了“ORDER BY”子句,对MATCH查询返回的结果进行排序。
我们可以按升序或降序对行进行排序。
默认情况下,它按升序对行进行排序。 如果我们要按降序对它们进行排序,我们需要使用DESC子句。
创建数据
1 | create(e:Employee{id:1001,name:"zhangsan",age:18}),(e2:Employee{id:1002,name:"lisi",age:15}),(e3:Employee{id:1003,name:"wangwu",age:30}) |
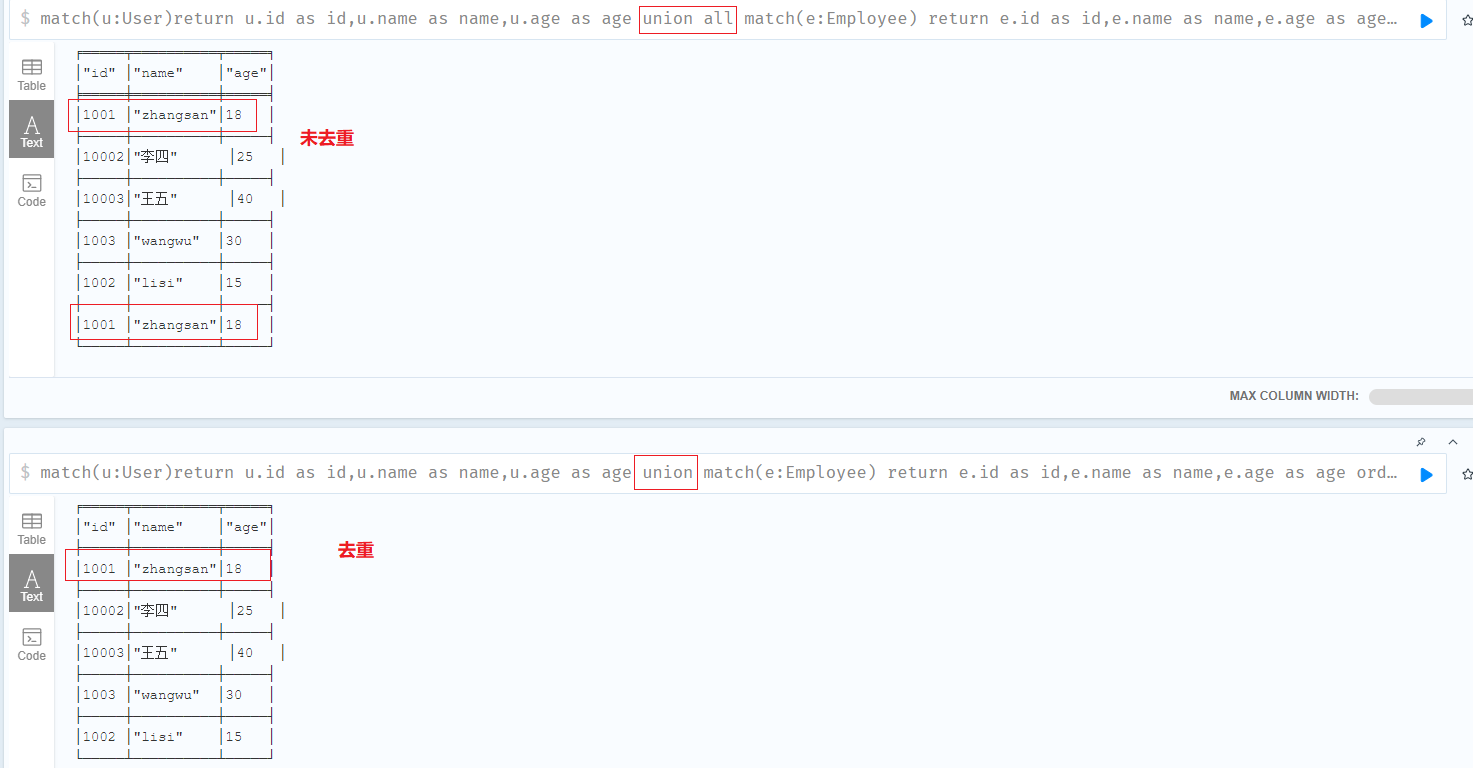
UNION
与SQL一样,Neo4j CQL有两个子句,将两个不同的结果合并成一组结果
- UNION:去重
- UNION ALL:不去重
创建User标签、Employee标签数据

1 | //union all |
注意添加别名,保持字段名一致,否则执行报错
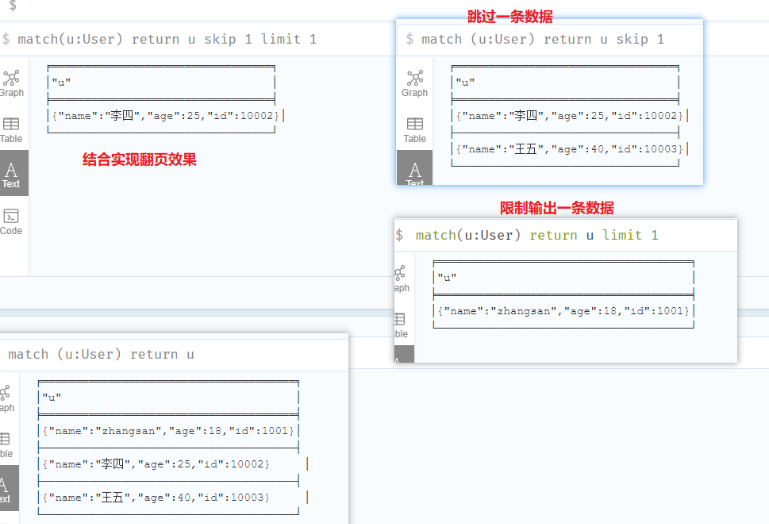
LIMIT和SKIP子句
通过limit限制输出获取数据
通skip跳过某些数据
两者结合可以实现翻页效果
1 | match (u:User) return u skip 1 |
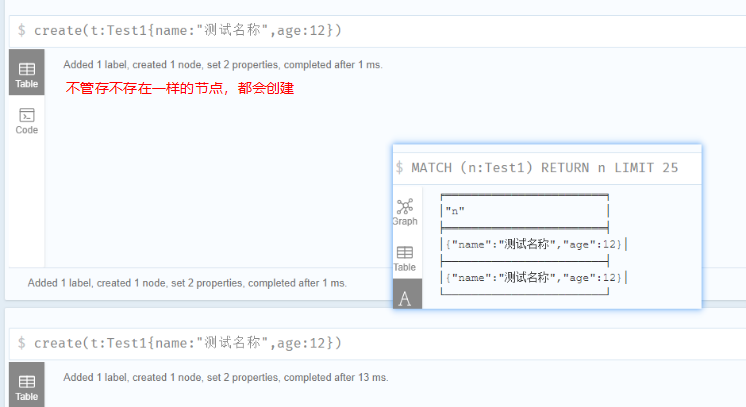
合并
Neo4j使用CQL MERGE命令 -
- 创建节点,关系和属性
- 为从数据库检索数据
MERGE命令是CREATE命令和MATCH命令的组合。
使用CREATE命令创建节点,不管存不存在一样的节点都会创建,MERGE命令如果不存在一样的节点就新建,存在则不处理
1 | create(t:Test1{name:"测试名称",age:12}) |
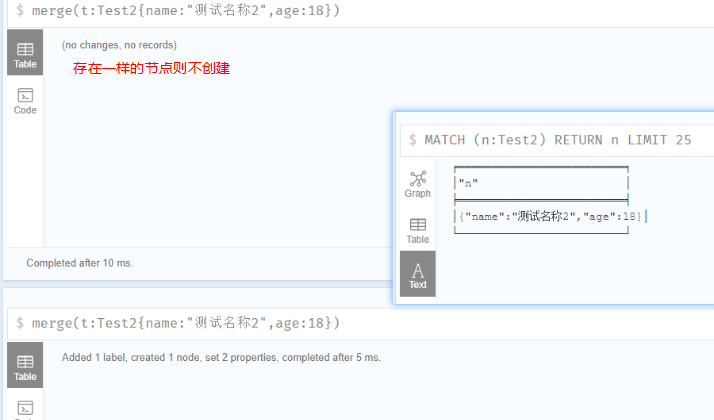
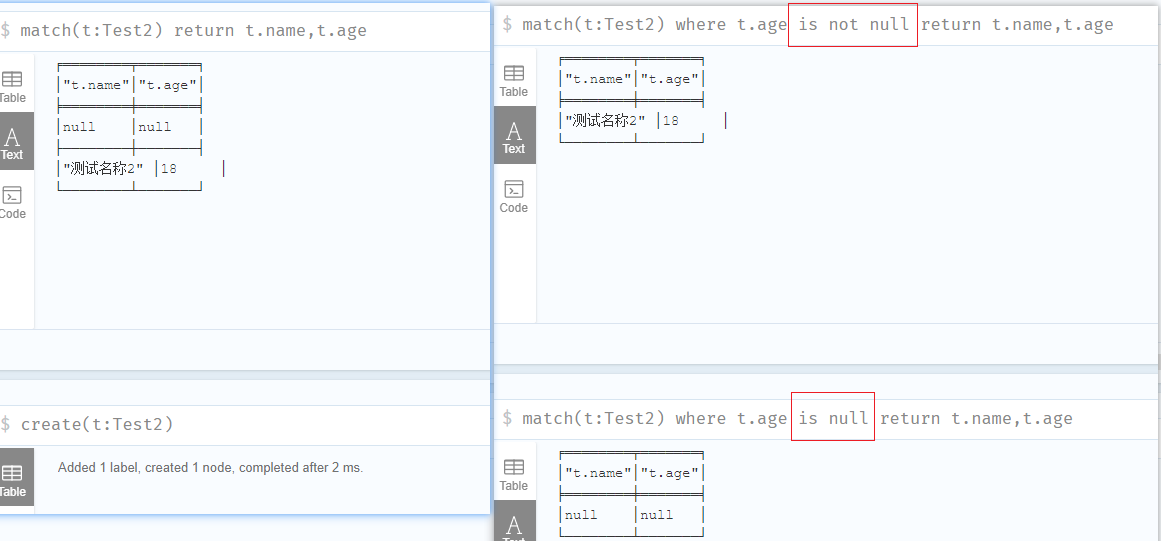
NULL值
当我们创建一个具有现有节点标签名称但未指定其属性值的节点时,它将创建一个具有NULL属性值的新节点。
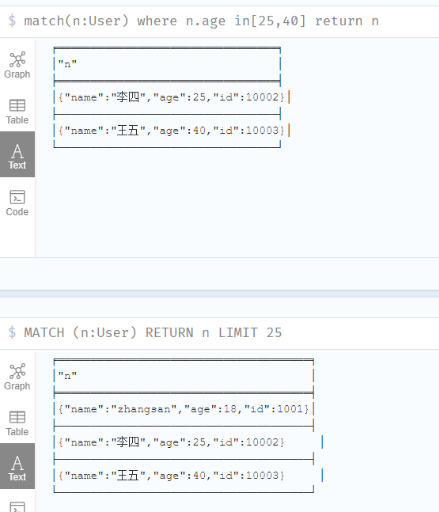
IN
1 | match(n:User) where n.age in[25,40] return n |
CALL
查询所有标签
1 | CALL db.labels() |
查询所有关系
1 | CALL db.relationshipTypes() |
函数
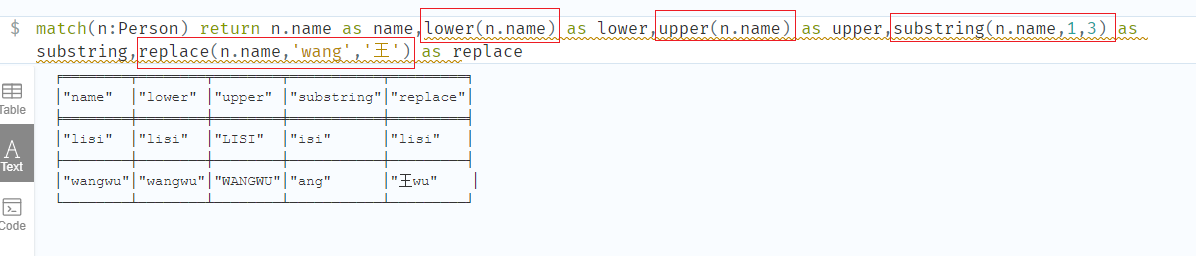
字符串函数
| 函数 | 描述 |
|---|---|
| upper | 转大写 |
| lower | 转小写 |
| substring | 截取字符串 |
| replace | 替换字符串 |
1 | match(n:Person) return n.name as name,lower(n.name) as lower,upper(n.name) as upper,substring(n.name,1,3) as substring,replace(n.name,'wang','王') as replace |
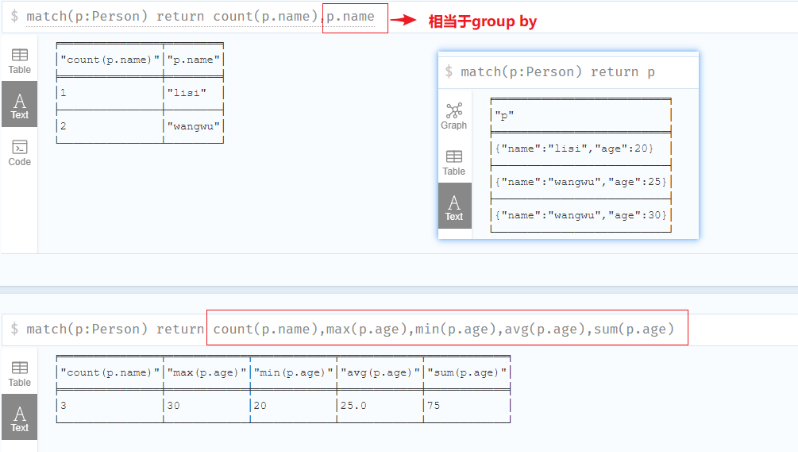
AGGEGATION聚合
和SQL一样,Neo4j CQL提供了一些在RETURN子句中使用的聚合函数。 它类似于SQL中的GROUP BY子句。
我们可以使用MATCH命令中的RETURN +聚合函数来处理一组节点并返回一些聚合值。
| 函数 | 描述 |
|---|---|
| count | 统计返回的行数 |
| max | 获取返回的最大值 |
| min | 获取返货的最小值 |
| sum | 所有返回数据累加求和 |
| avg | 所有返回数据求平均值 |
1 | //函数后面的p.name,相当于sql里面的group by p.name |
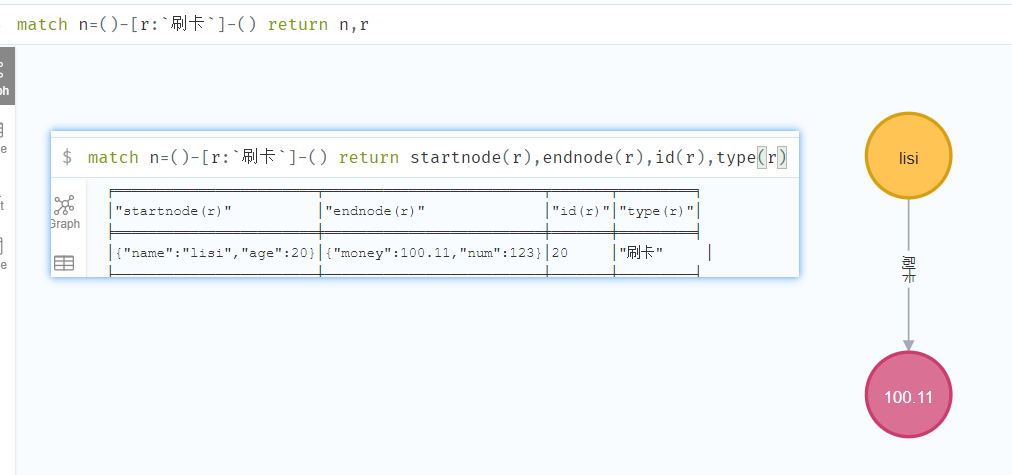
关系函数
Neo4j CQL提供了一组关系函数,以在获取开始节点,结束节点等细节时知道关系的细节。
| 函数 | 描述 |
|---|---|
| startnode | 用于查找关系的开始节点 |
| endnode | 用于查找关系的结束节点 |
| id | 用于查找关系的id |
| type | 用于查找关系的类型,即关系的名称 |
1 | match n=()-[r:`刷卡`]-() return startnode(r),endnode(r),id(r),type(r) |