UUID
随机无序
不适合Innodb引擎的使用,新增数据造成随机写、B+树页分页等情况
Redis
原子性自增返回数值
优点:简单、性能高
缺点:暴露业务增长量
数据库
主键自增
基于数据库表主键自增获取id
1 | CREATE TABLE t_sequence_id ( |
缺点:并发性能差,暴露业务增长量
多库跨步长取号
第一台数据库
1
2set @@auto_increment_offset = 1; -- 起始值
set @@auto_increment_increment = 2; -- 步长第二台数据库
1
2set @@auto_increment_offset = 2; -- 起始值
set @@auto_increment_increment = 2; -- 步长
相比于单机数据库,并发性能通过增加数据库实例解决。
缺点:但无法动态增加,新增取号数据库需要手动修改步长,修改期间不停服可能造成重复ID出现。
号段
每次从数据库获取ID时,就获取一个号段,比如(1,1000],这个范围表示了1000个ID,业务系统缓存号段数据。
当前号段数据使用达到一定阈值时,回库再取。
1 | CREATE TABLE id_generator ( |
业务系统获取时通过分布式锁或者版本号机制保证并发安全,修改数据库数据,获取号段数据缓存在jvm内存,提供给用户访问
雪花算法
原始雪花算法
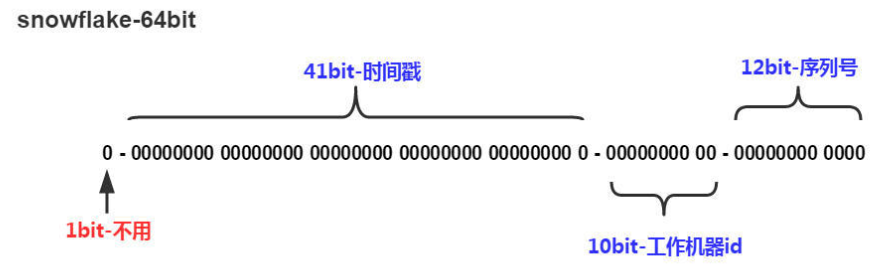
- 1bit - 无符号位:在java中由于long的最高位是符号位,正数是0,负数是1,一般生成的ID为正数,所以固定为0。
- 41bit - 时间戳:毫秒级的时间,一般实现上不会存储当前的时间戳,而是时间戳的差值(当前时间-固定的开始时间),这样可以使产生的ID从更小值开始;41位的时间戳可以使用69年,(1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69年。
- 10bit - 机器id:取决于用户如何使用,可以使用前5位作为数据中心机房标识,后5位作为单机房机器标识,可以部署1024个节点。
- 12bit - 序列号:支持同一毫秒内同一个节点可以生成4096个ID。
无符号位+时间戳+机器号+序列号,会出现时间回拨问题
百度 - uid-generator
使用雪花算法模式,又跟原始的雪花算法不同
可以自己去定义workId的生成策略,默认提供的策略是:应用启动时由数据库分配。
应用在启动时会往数据库表(uid-generator需要新增一个WORKER_NODE表)中去插入一条数据,数据插入成功后返回的该数据对应的自增唯一id就是该机器的workId,而数据由host,port组成。
- sign(1bit)
固定1bit符号标识,即生成的UID为正数。 - delta seconds (28 bits)
当前时间,相对于时间基点”2016-05-20”的增量值,单位:秒,最多可支持约8.7年 - worker id (22 bits)
机器id,最多可支持约420w次机器启动。内置实现为在启动时由数据库分配,默认分配策略为用后即弃,后续可提供复用策略。 - sequence (13 bits)
每秒下的并发序列,13 bits可支持每秒8192个并发。
美团 - leaf
支持号段、雪花算法模式
解决雪花算法时间回拨问题
服务启动向zk注册两节点
- 持久节点,存储当前服务器时间,定时更新
- 临时节点,存入当前服务器ip+port
检查当前时间是否小于之间持久节点存储的时间,小于则启动失败
获取临时节点地址,请求他们的服务器时间取平均值与当前时间相见,偏差值超过阈值则启动失败
Mongodb - ObjectId
12 字节的ObjectId
- 一个 4 字节的时间戳,表示 ObjectId 的创建,以自 Unix 纪元以来的秒数为单位。
- 每个进程生成一次的 5 字节随机值。这个随机值对于机器和过程是唯一的。
- 一个 3 字节递增计数器,初始化为一个随机值。