一、存储
- 代理节点(Broker):Kafka集群组建的最小单位,消息中间件的代理节点;
- 主题(Topic):用来区分不同的业务消息;
- 分区(Partition):Topic物理意义上的分组,一个Topic可以分为多个Partition,每个Partition是一个有序的队列;
- 片段(Segment):每个Partition又可以分为多个Segment文件;
- 偏移量(Offset):每个Partition都由一系列有序的、不可修改的消息组成,这些消息被持续追加到Partition中,Partition中的每条消息记录都有一个连续的序号,用来标识这条消息的唯一性;
- 消息(Message):Kafka系统中,文件存储的最小存储单位。
Kafka系统中的Message是以Topic为基本单位,不同的Topic之间是相互独立、互不干扰的。每个Topic又可以分为若干个Partition,每个Partition用来存储一部分的Message。
1.1、分区存储
Kafka系统在创建主题(Topic)时,它会规划将分区分配到各个代理节点(Broker)。
例如,现有3个代理节点,创建一个包含3个分区(Partition)、3个副本的主题(Topic),那么Kafka系统中会有9个分区副本分别被分配到3个代理节点。其中有3个leader分区,每个leader分区有2个副本分区。
在Kafka系统中,一个主题(Topic)下包含多个不同的分区(Partition),每个分区为单独的一个目录,分区的命名规则为:主题名+有序序号,第一个分区的序号从正整数0开始,序号最大值等于分区总数减1。 主题的存储路径由“log.dirs”属性决定。

每个分区(Partition)相当于一个超大的文件被均匀分配成若干个大小相等的片段(Segment),由配置文件log.segment.bytes指定切分大小
片段(Segment)文件由索引文件和数据文件组成,其中后缀为“.index”表示索引文件,后缀为“.log”的表示数据文件。

Kafka系统中的索引文件并没有给数据文件中的每条消息记录都建立索引,而是采用了稀疏存储的方式,每隔一定字节的数据来建立一条索引。
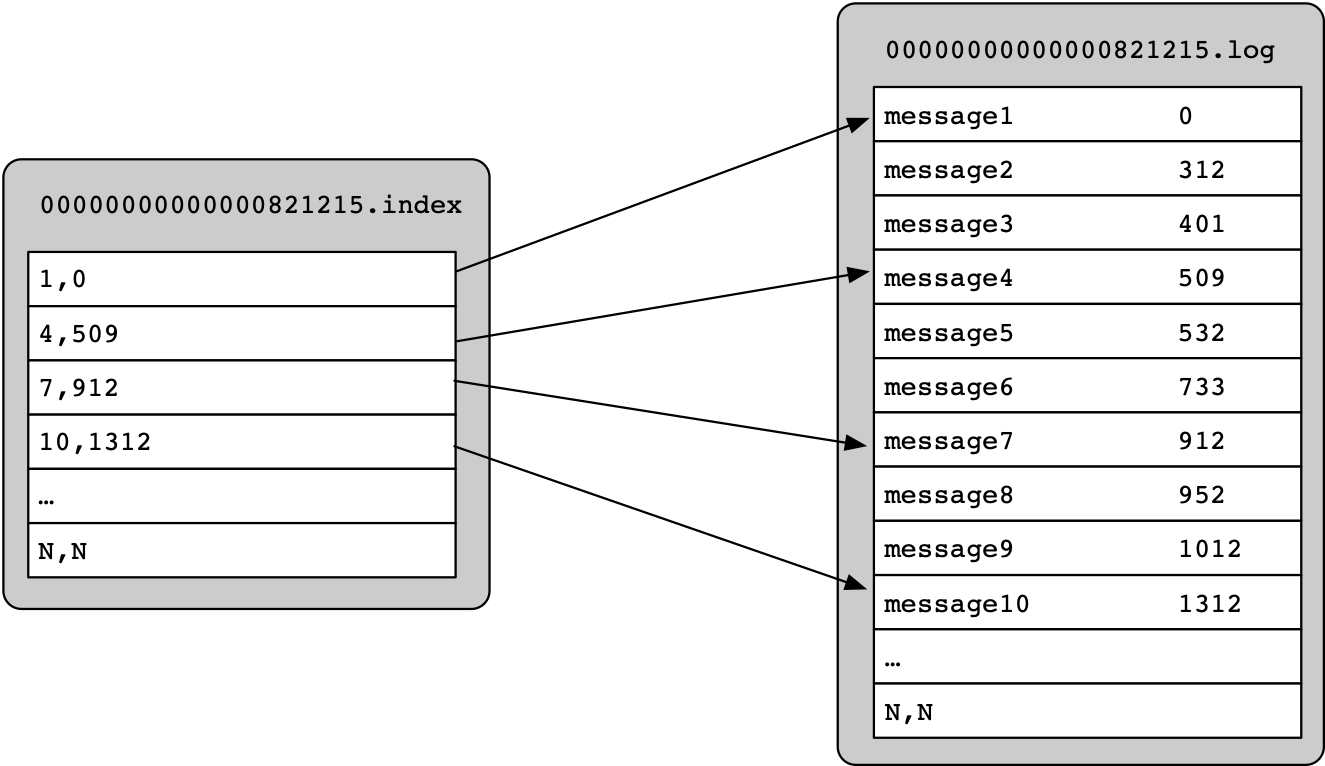
通过稀疏存储索引的方式,避免了索引文件占用过多的磁盘空间。从而将索引文件存储在内存中,虽然没有建立索引的Message不能一次性定位到所在的数据文件上的位置,但是因为有稀疏索引的存在,会极大的缩小顺序扫描的范围。
1.2、消息格式
Kafka使用固定长度的消息切分方式处理二进制传输数据,在消息前面固定长度的几个字节中记录这条消息的大小(单位为byte)
1 | Message => Crc MagicByte Attributes Key Value |

二、过期数据
Kafka系统在清理过期的消息数据时,提供了两种清除策略。它们分别是:
- 基于时间和大小的删除策略;
- 压缩(Compact)清理策略。
这两种策略通过属性“log.cleanup.policy”来控制,可选值包含“delete”、“compact”,其默认值为“delete”。
1 | ############################# Log Retention Policy ############################# |
2.1、删除策略
按照时间删除
1 | #系统默认保存7天 |
按照保留大小来删除过期数据
1 | # 系统默认没有设置大小 |
同时配置时间和大小,来进行设置混合规则。一旦日志大小超过阀值就清除分区中老的片段数据,或者分区中某个片段的的数据超过保留时间也会被清除。
2.2、压缩策略
如果要使用压缩策略清除过期日志,需要显示的指定属性“log.cleanup.policy”的值为“compact”。压缩清除,只能针对特定的主题应用,即写的消息数据都包含Key,合并相同Key的消息数据,只留下最新的消息数据。