一、分区
在Kafka系统中,一个主题(Topic)下包含多个不同的分区(Partition),每个分区(Partition)相当于一个超大的文件被均匀分配成若干个大小相等的片段(Segment)。
Kafka可以保证分区上的消息是有序的,不同分区之间的消息没有顺序。
分区可以设置副本因子,其中Leader分区负责对应分区的读写、Follower分区负责同步分区的数据。
二、ISR(In sync replicas)
Leader分区会维持一个与其保持同步的replica集合,该集合就是ISR。
当开启Ack机制时,Leader分区收到数据后,后面的Follower就开始同步数据了,但是如果有一个Follower出现了故障,无法与Leader来进行同步,这样Leader就会一直等待下去了,直到它同步完成才会把Ack发送出去。这种情况下会大大的让Kafka效率降低,所以ISR就出现了。
旧版本通过消息数量控制剔除ISR阈值,而新版本通过时间阈值控制,避免瞬间大批消息造成Follower频繁的剔除加入
1 | # kafka 0.9.0 版本之前存在的参数 |
2.1、ACK的应答机制
Kafka对数据的可靠性要求不是非常的高,就是可以说是容忍那么一丢丢的数据丢失,可以不等待ISR里的Follower全部接收成功。
通过指定生产者ACK参数,决定其应答方式:
- acks=0(默认):producer不等待broker的ack,这一个操作是提供了最低的一个延迟,使得broker一接收到还没来得及写入磁盘的时候就已经返回了,当broker出现故障的时候就会可能丢失数据。
- acks=1:producer等待broker的ack,partition的Leader落盘成功以后返回了ack,如果follwer在同步成功之前发生了故障的话,那么就会把数据丢失掉。
- acks=-1/all:producer等待broker的ack,partition的Leader和Follower需要全部落盘成功之后才会返回ack,但是如果在Follower同步完成之后,在broker在发送ack前,Leader发生了故障,那么可能会造成数据的重复。
2.2、Follower故障
Follower发生故障后会被临时踢出ISR(动态变化),待该Follower恢复后,Follower会读取本地的磁盘记录的上次的HW,并将该log文件高于HW的部分截取掉,从HW开始向Leader进行同步,等该Follower的LEO大于等于该Partition的HW,即Follower追上Leader后,就可以重新加入ISR
2.3、Leader故障
Leader发生故障后,会从ISR中选出一个新的Leader,为了保证多个副本之间的数据一致性,其余的Follower会先将各自的log文件高于hw的部分截掉(新Leader自己不会截掉),然后从新的Leader同步数据。
三、LEO(log end offset )
log end offset 标识的是每个分区中最后一条消息的下一个位置,分区的每个副本都有自己的LEO.
四、High Watermarker(高水位线)
4.1、作用
- 定义消息可见性,确定哪些数据对于消费者可以进行消费
- 协助Kafka副本分区间完成同步(0.11 版本之前Kafka使用HW机制保证数据的同步,但是基于HW的同步数据可能会导致数据的不一致、数据丢失等情况,后续版本改用Leader Epoch)
HW(High Watermark)是所有副本中最小的LEO。
当所有节点都备份成功,Leader会更新水位线,所有HW之前的的数据才可以被消费者消费。
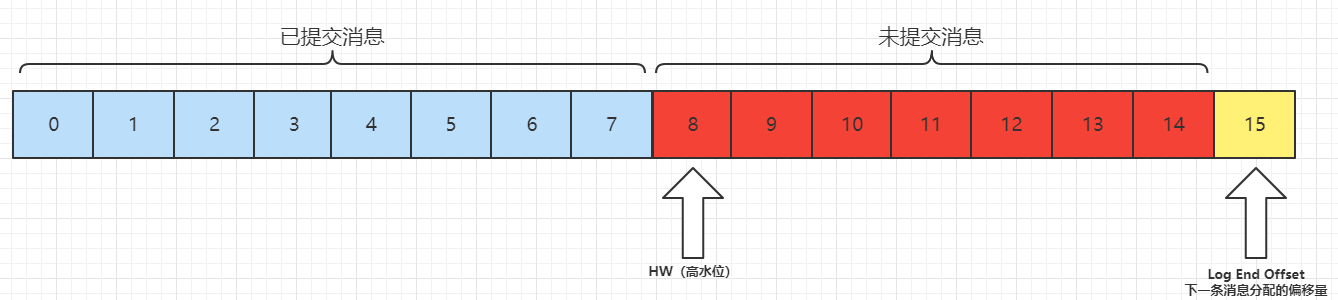
如上图,0-7的已提交的消息可以被消费者消费,8开始的消息对于消费者不可见。
4.2、更新
每个分区副本都保存一组HW和LEO值,并且Leader分区副本所在的Broker上,还保存了其他Follower分区副本的LEO值,这些Follower分区副本又被称为远程副本(Remote Replica)
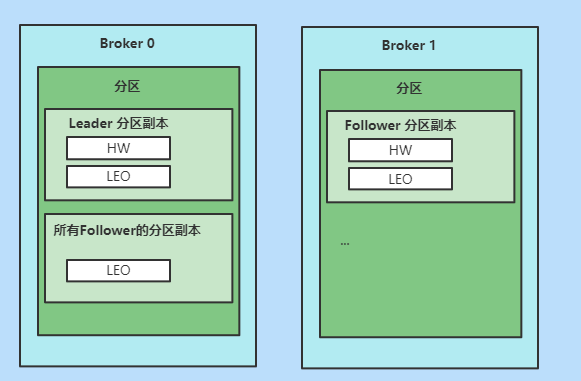
- 更新
- Broker0上的Leader分区副本的HW和LEO,以及所有Follower分区副本的LEO
- Broker1上的Follower的HW和LEO
- 不更新
- Broker0上所有Follower分区副本的HW
为什么要在 Broker0 上保存这些 Follower 副本呢?
- 帮助 Leader 副本确定其高水位,也就是分区高水位。
4.2.1、更新时机
| 更新对象 | 更新时机 |
|---|---|
| Borker0 上Leader分区副本的LEO | Leader分区副本接收到生产者发送的消息,写入到本地磁盘后,会更新其LEO值 |
| Broker 1上Follower分区副本的LEO | Follower分区副本从Leader分区副本拉取消息,写入本地磁盘后,会更新其LEO值 |
| Broker0上远程副本的LEO | Follower分区副本从Leader分区副本拉取消息,会告诉Leader分区副本从哪个位移开始拉取,Leader分区副本会使用这个位移来更新远程副本的LEO |
| Broker0上Leader副本的高水位 | 两个更新时机:一个是Leader副本更新其LEO之后,一个是更新完远程副本LEO后,具体算法:取Leader分区副本和所有与Leader同步的远程副本LEO的最小值 max{currentHW, min(LEO-1, LEO-2, ……,LEO-n)} |
| Broker 1上Follower副本的高水位 | Follower副本更新完LEO后,会比较LEO与leader副本发来的高水位值,并用两者的较少值去更新自己的高水位 |
4.2.2、流程
Leader分区副本
处理生产者请求
- 消息写入本地磁盘
- 更新LEO值(触发更新HW)
- 获取所有远程副本中最小的LEO值
- 获取当前HW值
- 更新 currentHW = max{currentHW, min(LEO-1, LEO-2, ……,LEO-n)}
Follower拉取Leader分区消息
- 读取磁盘(页缓存)数据
- Follower分区副本在请求时会携带其LEO值,更新远程分区副本的LEO值(触发更新HW)
- 获取所有远程副本中最小的LEO值
- 获取当前HW值
- 更新 currentHW = max{currentHW, min(LEO-1, LEO-2, ……,LEO-n)}
Follower分区副本
- 从Leader分区拉回数据
- 消息写入本地磁盘
- 更新LEO值(触发更新HW)
- 获取Leader返回的高水值,currentHW
- 获取更新后的LEO值,currentLEO
- 更新高水位为 min(currentHW, currentLEO)
4.2.3、同步
初始状态

这里的 Remote LEO 代表之前我们 Broker0 中的远程副本的 LEO,我们的 Follower 副本通过 FETCH 请求不断与 Leader 副本进行数据同步
生产者发送消息
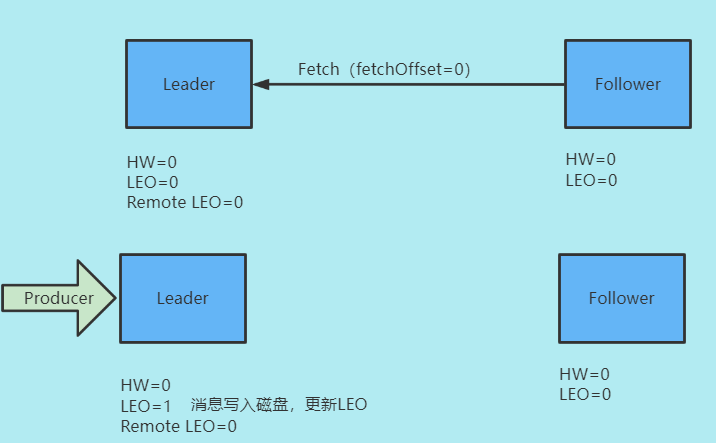
- 生产者消息写入磁盘,更新LEO
- 更新高水位
- 当前HW=0
- 远程副本LEO=0
- HW= Math.max(HW,最小远程副本LEO)= Math.max(0,0) = 0
第一次同步
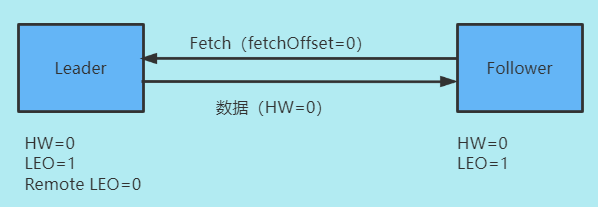
- Leader接收Follower请求
- 读取磁盘(页缓存)数据
- 根据Follower请求的offset,更新Remoto LEO = 0
- 更新HW(无变化)
- Follower拉回数据
- 写入本地磁盘,更新LEO值
- 更新高水位
- 获取 Leader 发送的高水位值:
currentHW = 0 - 获取更新后的LEO值,currentLEO = 1
- HW= Math.max(HW,最小远程副本LEO) = Math.max(0,0) = 0
- 获取 Leader 发送的高水位值:
经过这一次拉取, Leader 和 Follower 副本的 LEO 都是 1,各自的高水位依然是0,没有被更新
第二次同步
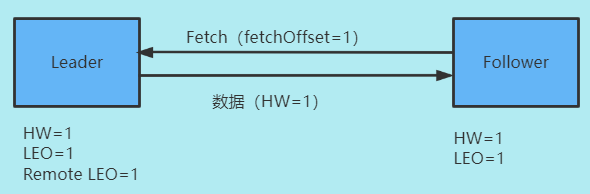
- Leader接收Follower请求
- 读取磁盘(页缓存)数据
- 根据Follower请求的offset,更新Remoto LEO = 1
- 更新HW= Math.max(HW,最小远程副本LEO) = Math.max(0,1) = 1
- Follower拉回数据
- 写入本地磁盘,更新LEO值(无变化)
- 更新高水位
- 获取 Leader 发送的高水位值:
currentHW = 1 - 获取更新后的LEO值,currentLEO = 1
- HW= Math.max(HW,最小远程副本LEO) = Math.max(1,1) = 1
- 获取 Leader 发送的高水位值:
至此,一次完整的消息同步周期就结束了。事实上,Kafka 就是利用这样的机制,实现了 Leader 和 Follower 副本之间的同步。
4.3、数据丢失
截断后立即进行领导人选举
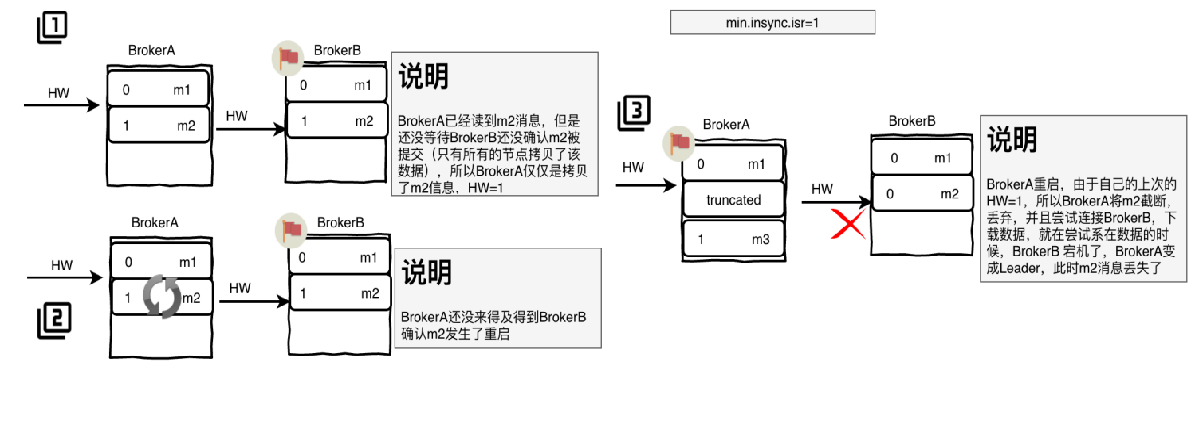
BrokerB是分区的Leader,当BrokerA读到m2消息,但是没有等到BrokerB确认m2消息提交(BrokerB等待所有节点拷贝数据),此时BrokerA只是拷贝了m2消息,其HW仍为1.
BrokerA还没得到BrokerB确认m2消息,此时BrokerA宕机
BrokerA重启,根据HW=1,将m2消息截断丢弃,尝试连接BrokerB下载数据,此时BrokerB宕机,BrokerA成为分区Leader,此时m2消息丢失
4.4、数据不一致
在多次硬故障后重新启动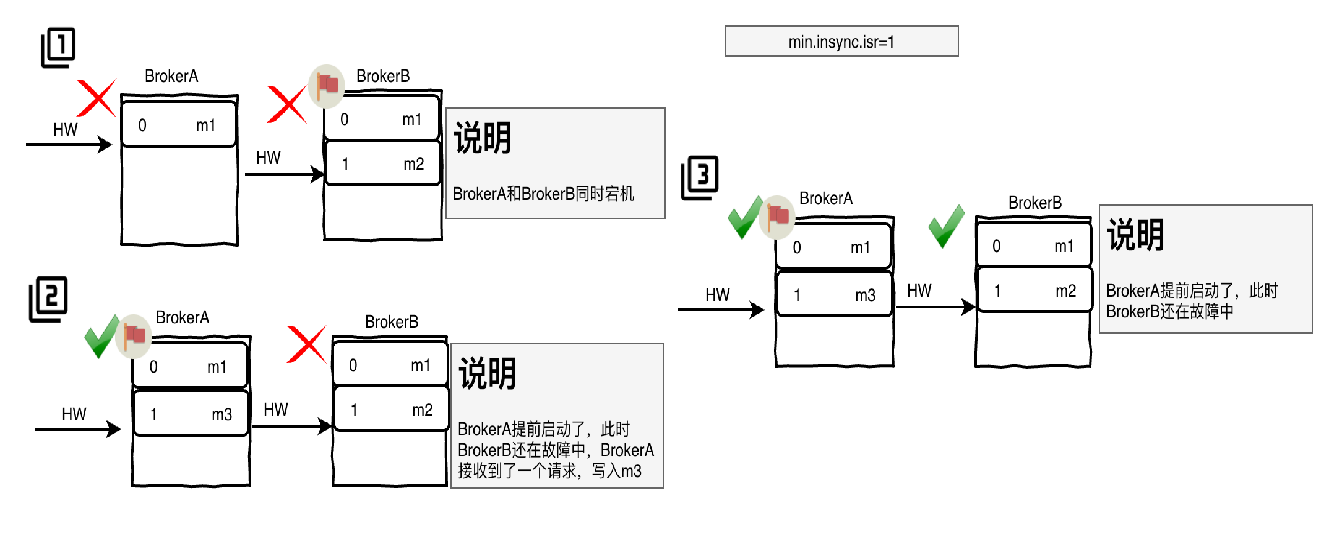
- BrokerB是分区的Leader,有m2消息,HW=1
- BrokerA和BrokerB同时宕机
- BrokerA先启动,成为Leader,此时接收请求,写入m3消息,HW=1
- BrokerB启动后,两个Broker的HW都是1,但是数据不一致
五、Leader epoch
由于0.11版本之前Kafka的副本备份机制的设计存在问题。依赖HW的概念实现数据同步,但是存在数据不一致问题和丢失数据问题。
因此Kafka-0.11版本引入了 Leader Epoch解决这个问题,不在使用HW作为数据截断的依据。
引入了Leader epoch的概念,任意一个Leader持有一个LeaderEpoch。该LeaderEpoch这是一个由Controller管理的32位数字,存储在Zookeeper的分区状态信息中,并作为LeaderAndIsrRequest的一部分传递给每个新的Leader。
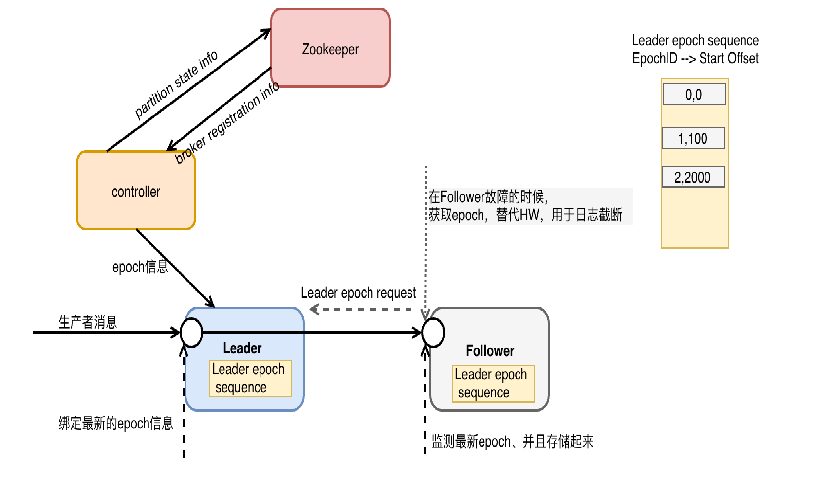
每个消息集都带有一个4字节的Leader Epoch号。
在每个日志目录中,会创建一个新的Leader Epoch Sequence文件,在其中存储Leader Epoch的序列和在该Epoch中生成的消息的Start Offset。它也缓存在每个副本中,也缓存在内存中。
也就是说Leader epoch实际上是一对值:(epoch,startOffset)
- epoch表示Leader的版本号,从0开始,当Leader变更过1次时epoch就会+1
- startOffset对应于该epoch版本的Leader写入第一条消息的位移
Follower宕机重启后需要做数据恢复时,会发送Leader Epoch Request获取Leader分区的Leader Epoch信息,Follower根据这些信息进行数据截断,替代旧版本通过高水位截断日志的方式。
5.1、Follower成为Leader
首先将新的Leader Epoch和Follower分区副本的LEO(log end offset)添加到Leader Epoch Sequence序列文件的末尾并刷新数据。该Leader产生的每个新消息集都带有新的“Leader Epoch”标记。
5.2、Leader变成Follower
Leader从本地的Leader Epoch Sequence文件加载数据到内存中
其他Follower给相应的分区的Leader发送epoch请求,该请求包含当前节点最新的EpochID、StartOffset信息。
Leader接收到信息以后返回该EpochID所对应的LastOffset信息。该信息可能是最新EpochID的StartOffset或者是当前EpochID的Log End Offset信息.
5.3、同步数据
当发生宕机重启时,Follower向Leader发送请求Epoch请求
- Leader根据Follower请求携带的epoch判断
- epoch相同,则返回最新的last offset
- epoch不同,则返回对应epoch的start offset
- Follower根据返回的offset与当前offset比较
- Follower的offset大,则截断数据- Follower的offset小,则同步数据
不再依靠高水位截断数据,而是依靠Leader Epoch有效的解决数据丢失和数据不一致问题
5.4、解决数据丢失
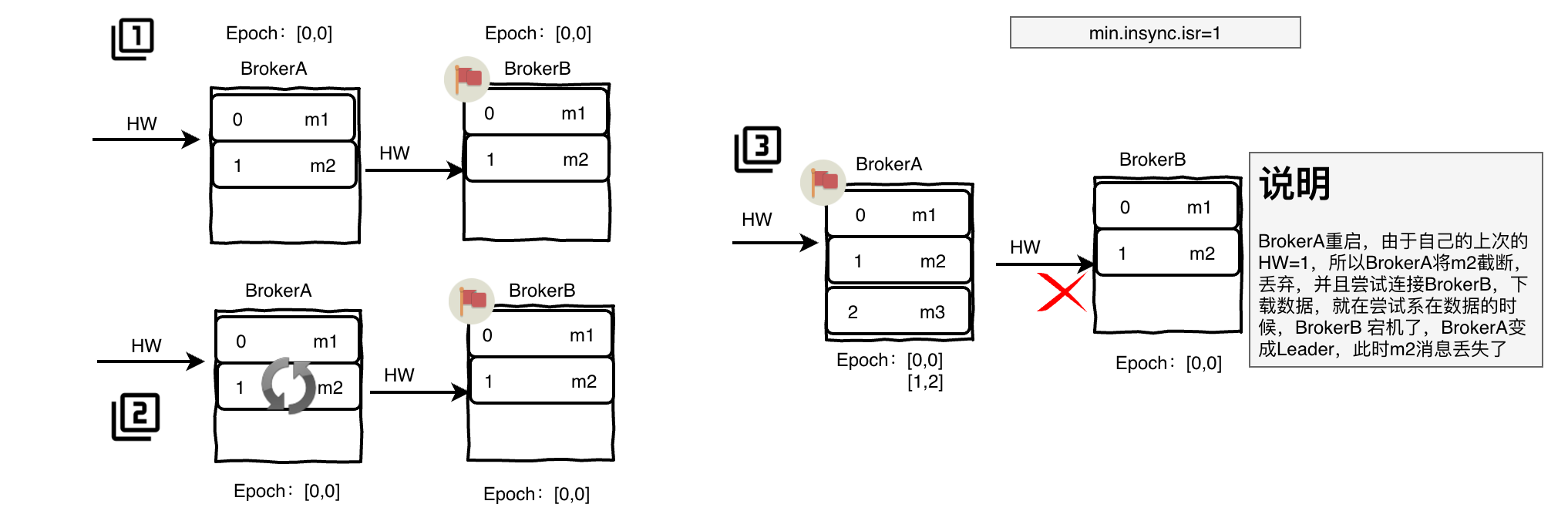
- BrokerA宕机重启后,不再依赖于HW截断数据
- 当BrokerB宕机,BrokerA成为Leader,Epoch数据更新为[1,2]
- 期间BrokerA有数据写入
- BrokerB重启后,向Leader发送Epoch请求,同步数据
5.5、解决数据不一致
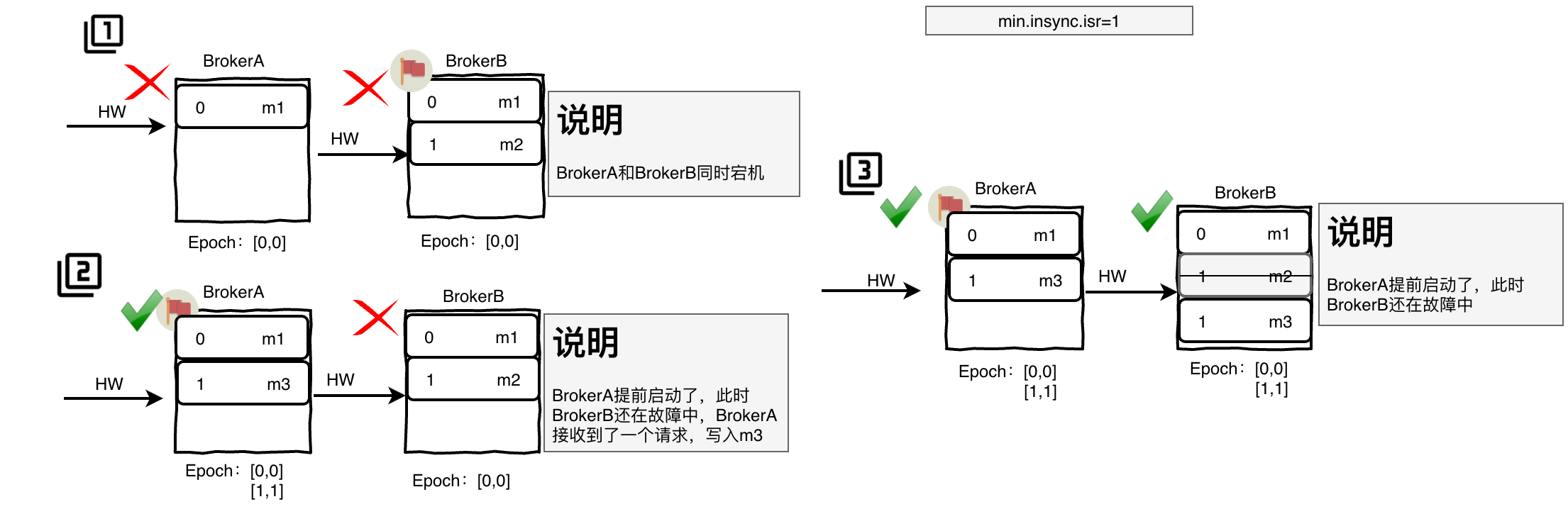
- BrokerA和BrokerB都宕机
- BrokerA先启动,成为Leader,接收数据m3
- BrokerB启动,向LeaderEpoch请求,截断自己offset为1的数据,再从Leader同步新数据