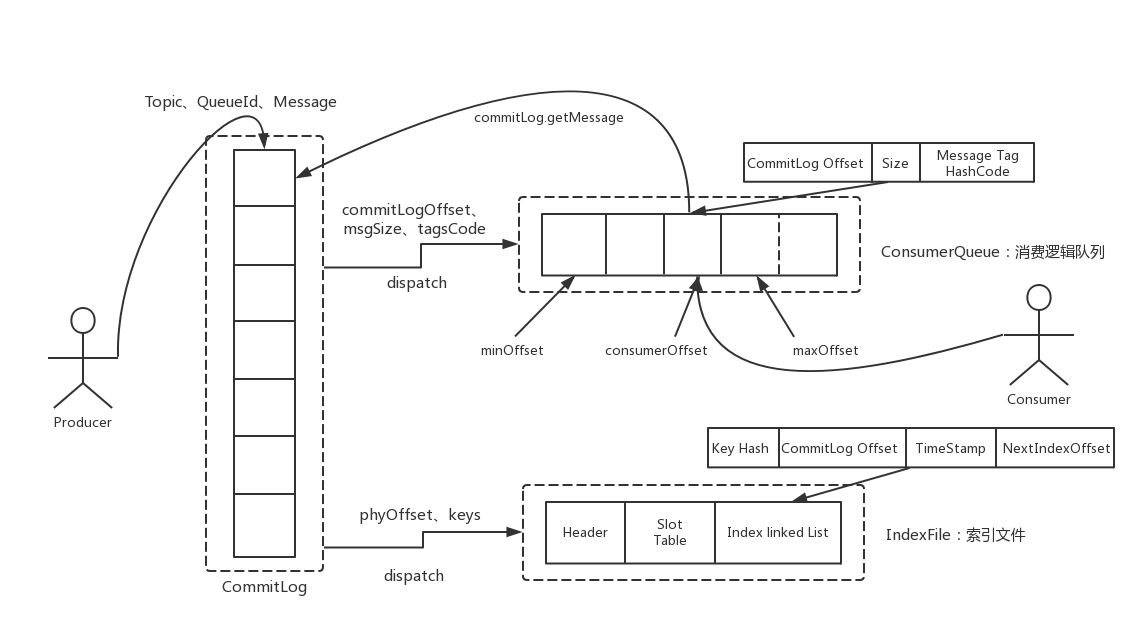
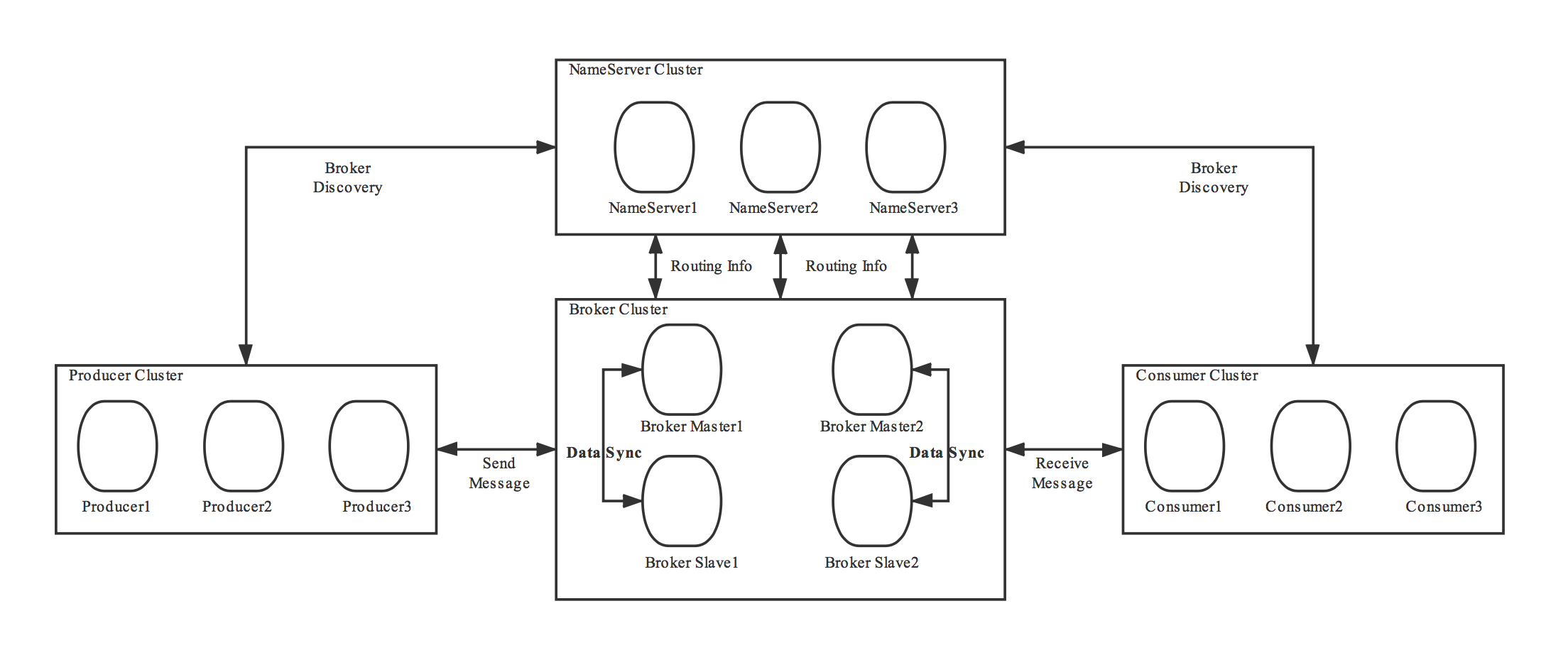
rocketmq-架构
组成
系统中的数据,随着业务的发展和时间的推移, 将会非常多, 而业务中往往采用模糊查询进行数据的搜索,而模糊查询会导致查询引擎放弃索引,从而导致系统查询数据时都是全表扫描,在百万级别的数据库中查询效率是非常低下的,而我们使用ElasticSearch做一个全文索引,将经常查询的系统功能中的某些字段放入 ElasticSearch索引库里,可以提高查询速度。
ElasticSearch 的选举是 ZenDiscovery 模块负责的,主要包含 Ping (节点之间通过这个 RPC 来发现彼此)和 Unicast (单播模块包含一个主机列表以控制哪些节点需要 ping 通)这两部分
1、对所有可以成为 master 的节点(node.master: true)根据 nodeId 字典排序,每次选举每个节点都把自
己所知道节点排一次序,然后选出第一个(第 0 位)节点,暂且认为它是 master 节点。
2、如果对某个节点的投票数达到一定的值(可以成为 master需要的节点数为: n/2+1 )并且该节点自己也选举自己,如果都符合,那这个节点就是 master ,否则重新选举一直到满足上述条件。
master节点的职责主要包括集群、节点和索引的管理,不负责文档级别的管理,此时master节点可以关闭node.data功能。
1 | unified:默认的高亮方式,使用Lucene的实现方式 |
TF数值大的得分较高,因为关键词在一个文档出现的次数多,证明该文档的相关性更大
IDF数值大的得分较低,关键词在整个倒排索引中出现的次数越多,关联的文档越多,证明其相关越低
relevance score(相关性得分):每个query的分数,乘以matched query数量,除以总query数量
ElasticSearch是基于Rest风格的操作,而Rest风格是一种软件架构风格,而不是标准,它只是提供了一组设计原则和约束条件。它主要用于客户端和服务器交互类的软件。基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。
| method | url地址 | 描述 |
|---|---|---|
| PUT | ip:9200/索引名称/类型名称/文档id | 创建文档(指定文档id) |
| POST | ip:9200/索引名称/类型名称 | 创建文档(随机文档id) |
| POST | ip:9200/索引名称/类型名称/文档id/_update | 修改文档(过时) |
| POST | ip:9200/索引名称/_update/文档id | 修改文档 |
| DELETE | ip:9200/索引名称/类型名称/文档id | 删除文档 |
| GET | ip:9200/索引名称/类型名称/文档id | 通过文档id查询文档 |
| POST | ip:9200/索引名称/类型名称/_search | 查询所有数据 |